还在认为没有实验就不能发表论文?还在为不精通挖掘GEO,TCGA等数据库而痛苦不堪?还在为不知道如何找课题找靶点而苦恼?还在为不会那些高大上的图表而暗自伤神?快来参加莫速乎的用R语言进行科研数据挖掘实战会议吧,挖掘别人的数据,发表自己的文章,一次学习,不再报班!
本会议由于带着明确的目的性去学习R语言,且针对有/无R语言基础的学员均具有很大宽容性,自开班起就广受好评。随着近年来生物信息学技术的普及,R语言是每个科研工作者都有必要掌握的技能,以往漫无目的的学习R效果不理想,用R去进行科研数据挖掘,既学习了R又解决了实际科研问题。
用R语言挖掘公共数据库(TCGA/GEO)发表高分文章
无实验无数据没关系,用R语言挖掘别人的数据,发表自己的文章
两天一夜高强度实训,讲究实战,所有经验和盘托出
会后赠讲课录像便于反复复习(加密播放不零售,保障学员优势权利)
第三十一期 2021/10/16-17 (两天&一晚)
网络精讲班(直播授课,非录播) 微信群长期答疑
学完课程并掌握后能收获什么技能?
1.没有课题的时候找到课题,没有机制的时候挖掘机制。
2.为基金申请保驾护航,发表paper如虎添翼
3.掌握R语言的核心技能,掌握批量分析数据的能力,掌握自我迭代的思维体系
4.掌握表达谱芯片数据,RNAseq转录组数据,甲基化芯片数据,GEO数据库和TCGA数据库等数据的处理
5.科研绘图:常见科研需求自我满足不求人,特殊需求实现自己定制高端大气。
这是一份带有诚意且注重实战的数据挖掘课程。我们的目标是:一次学习,不再报班。
课程特点
1.不留秘密,私货全出,全程只用R语言,关键步骤不隐藏。
2.第一天晚上时间充分利用,增加带有讲师指导的练习,更多的训练时间,更好的掌握。
3.讲最核心的知识,讲通用的数据挖掘技能,适合各个专业。学后可应用到其他数据库的挖掘。
4.空谈误国,实例操作(至少4个套路),让你快速掌握数据挖掘套路。
5.课程中使用卡片记忆法,帮助学员迅速牢靠地记住R语言知识点。
6.讲师阵容强大,内容丰富深入, 课程设计循序渐进,渐入佳境。
涉及议题
1.如何使用生物信息学,在没有课题的时候如何找课题,在没有机制的找机制?2.科研中细胞系处理的两大刚需,加药以及基因敲减,有什么好的分析方案可以让我们精准定位到下游核心分子?3.为什么大部分公司给的分析结果都用不了啊,导师和我都很着急,怎么处理才能够变废为宝?4.GEO表达谱芯片数据如何挖掘分析,才能避免画个热图火山图,聚类图就草草了事?5.TCGA数据库中的数据,如何从下载到分析,到变成可以任意基因任意癌症轻松出图的清洁数据?6.生存分析的多种方案,包含一个基因的生存分析,两个基因的生存分析,一群基因的生存分析,8秒完成2万个基因的批量相关性分析。7.如何学会编程的看家本领,让重复的工作批量执行(批量分析,批量作图,批量处理文件)?8.构建临床预后模型的完整方案是什么?9.课题组比较关心免疫浸润分析,目前有哪些方案可以提供?10.我入门的有点晚了,数据都被别人挖完了,有什么开挂的解决方案?11.为什么做KEGG富集分析的时候,肝癌的数据会聚类出系统性红斑狼疮通路,我该怎么解释?12.给你一个基因,在不做实验的情况下,你对他能了解到什么程度,以及能产生多少可放在文章中的数据?13.给你两个基因,在不做实验的情况下,你对他们之间的关系能了解到什么程度,以及能产生多少可放在文章中的数据?14.给你一群基因,在不做实验的情况下,你对他们能了解到什么程度,以及能产生多少可放在文章中的数据?15.我做基础研究的,老板不需要纯生信的文章,数据挖掘怎么才能得体的用到自己课题上面来啊?16.差异分析是数据挖掘的灵魂,那么小样本,大样本,配对样本,多分组样本的差异分析怎么做?17.GSEA分析是富集分析的神器,他好在哪里,如何使用?如何用GSEA给自己的课题提速?18.ceRNA如何分析,分析的前提是要掌握mRNA,lncRNA,miRNA的分析19.目前的signature文章中有哪些埋好的雷等着你去踩?20.那么多的GEO平台,如何以不变应万变地进行探针ID转换?21.GEO多芯片数据如何批次矫正?22.为什么ssGSEA算法是批次效应的终结者?23.如何使用Guilt of association 方案注释手上的长链非编码RNA?24.单基因GSEA的用途在哪里?为什么出来的结果跟我想要的不一样? 25.我手上的样本有点多,WGCNA怎么做?26.如何才能提取出转移和非转移配对的TCGA样本出来进行下一步分析?27.我想进一步学习,但不想到处折腾了,有哪些你珍藏的资源推荐?28.你是通过什么途径学会自己想要的技能的?有什么固定的流程么?。。。
课程设计
这么多的内容显然是无法在两天1晚的课程中讲完,否则都是浮光掠影,空有其表。
因此,我们根据科研人学习的四个层面,把课程分成了四个部分。 第1,学会手把手教学的技能:
这部分内容就是课程的主体, 两天1晚的直播课程,配合动画,记忆卡片,大量实操循序渐进让学员迅速入门其中记忆卡片的使用,有效解决了"讲师口里一大堆,学员脑子一片白"的尴尬局面,这种情况会让学员迅速失去兴趣。经过测试,即使是零基础的学员也能在第1天结束后记住所教的R语言知识点第2,看视频学会技能:
该部分内容是附加课程,需要课后打卡自学,目的是让学员多操多练,渐入佳境。这部分技能比较硬核,不适合在课堂上讲解,需要学员在掌握基础技能的时候再慢慢深入。避免出现"脑子会了,手说不会"等手脑不协调的窘境。第3,看文字学会技能:
我们在课程的文档中穿插了100个文字教程,解决一些小而精巧的问题.这部分技能训练的是学员自学的能力,有利于让学员形成自我迭代的能力。在数据挖掘的过程中,并不是每一个技能都能找到合适的教程。生信工作者长期在做的事情就是阅读文档。第4,学会没有人教的技能:
课程结束后布置涉及到高频操作的家庭作业,作为对课程的巩固和升华,需要学员在一月内提交然后讲师团队评阅。这部分习题没有标准答案,类似于开放课题,要求学员通过自我学习,互相合作来完成。学会没人教的技能,是数据挖掘的常态,你不能老是重复别人的套路,因为"既是套路,就为俗物,终将废物"。我们希望将来在你思路到了的时候,要有能力从源头用代码来实现,而不是碰到了报错完全懵圈,不知进退。这是数据挖掘的终极技能。
学员效果展示
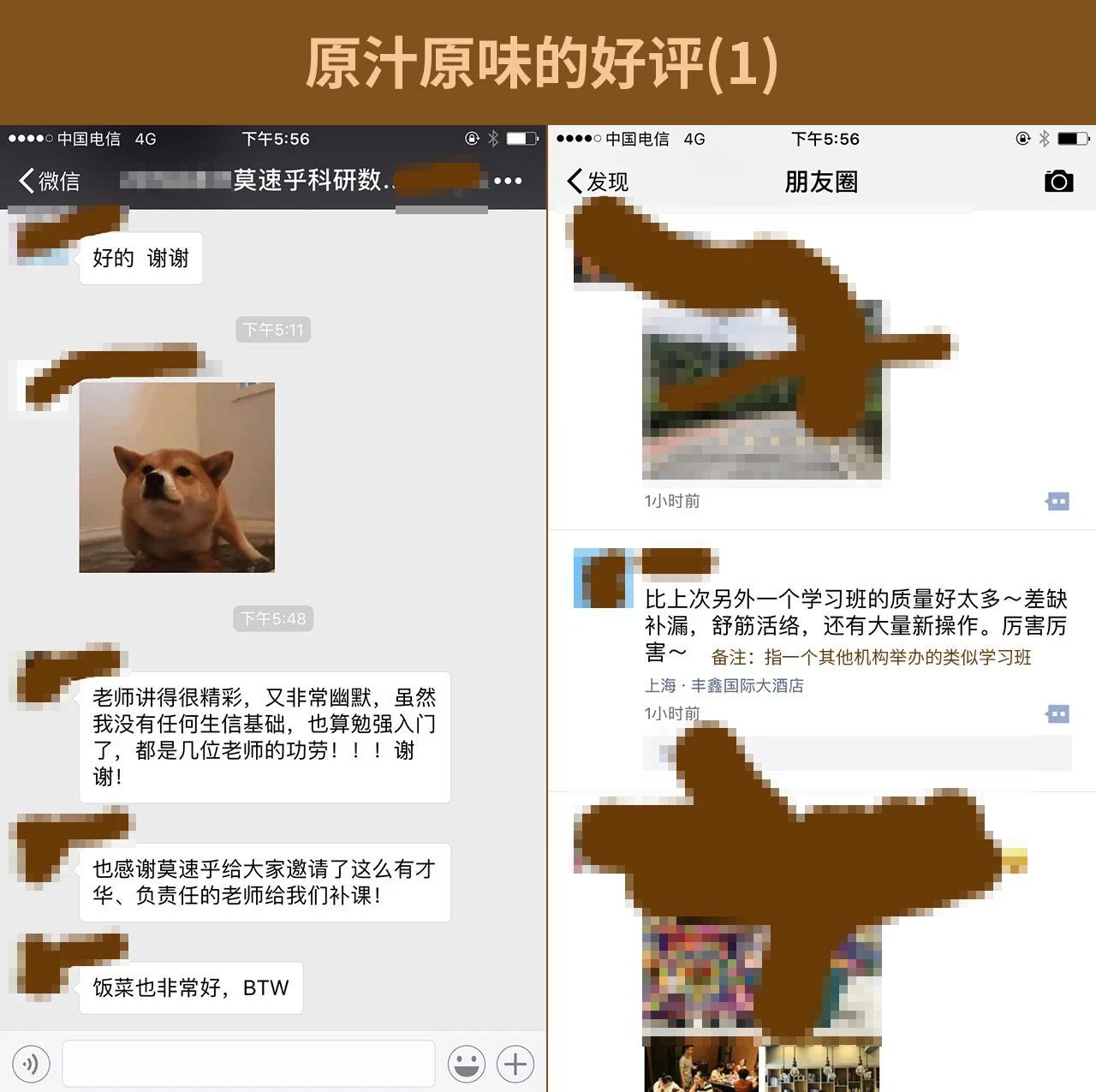
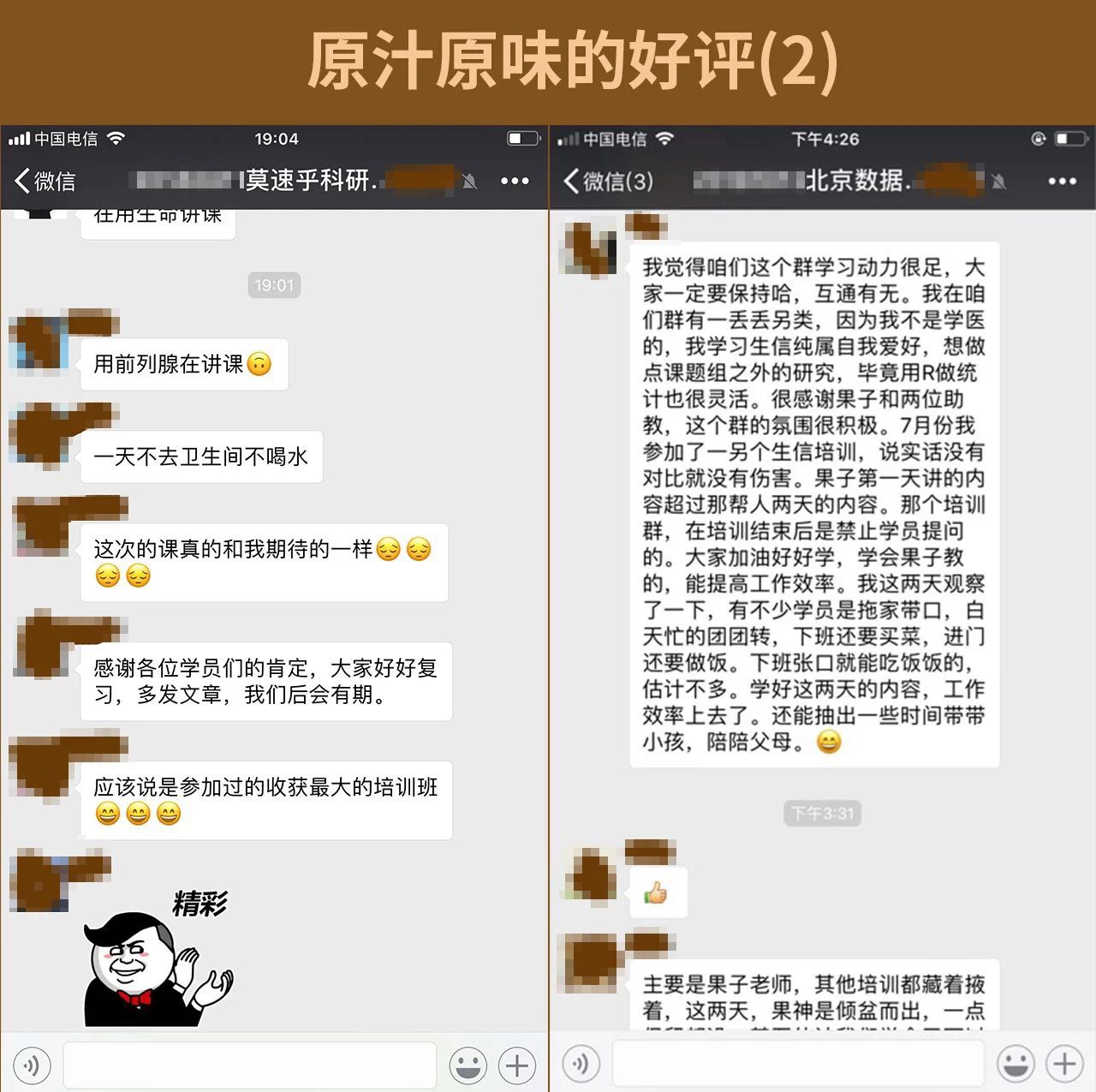
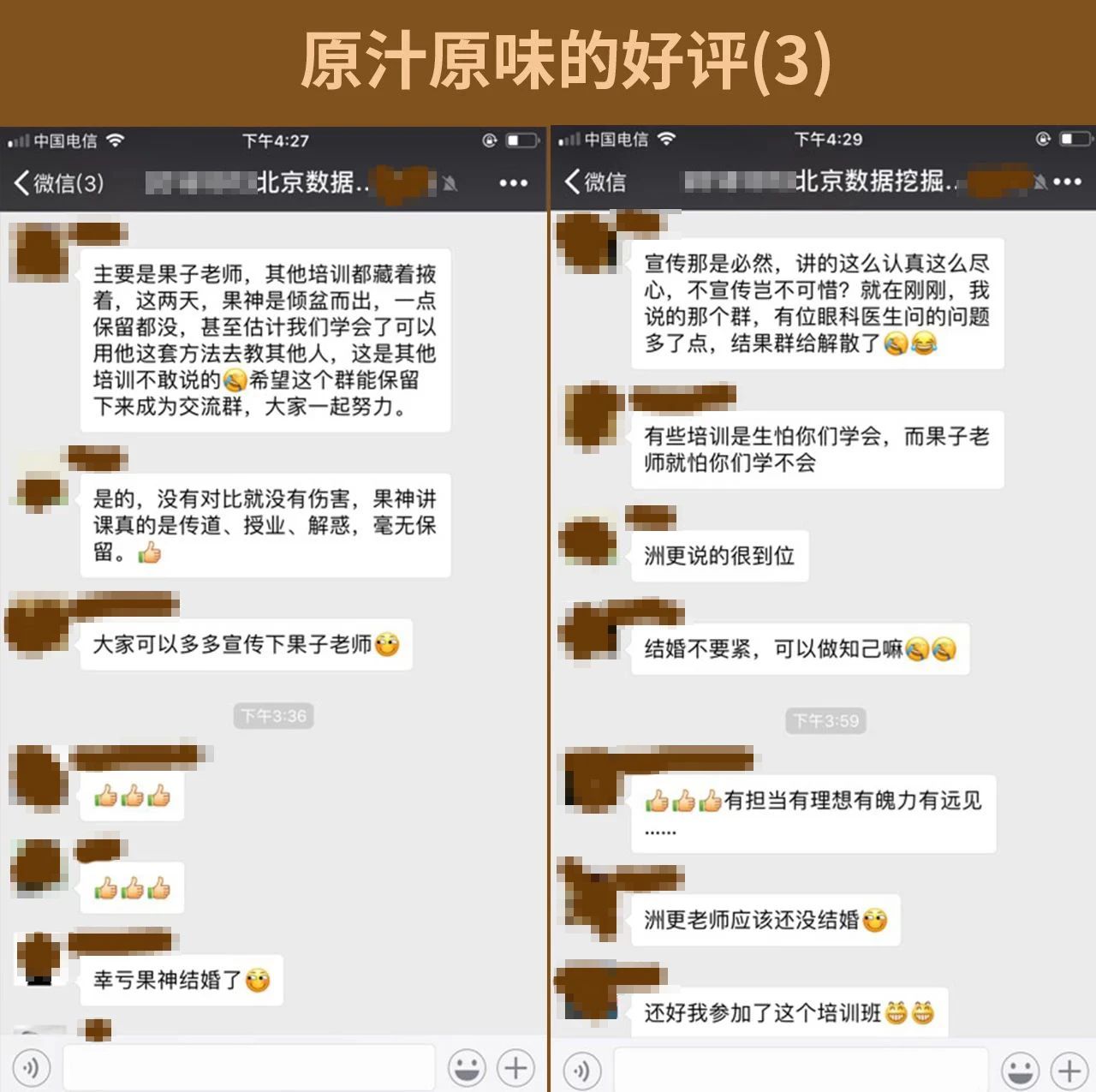
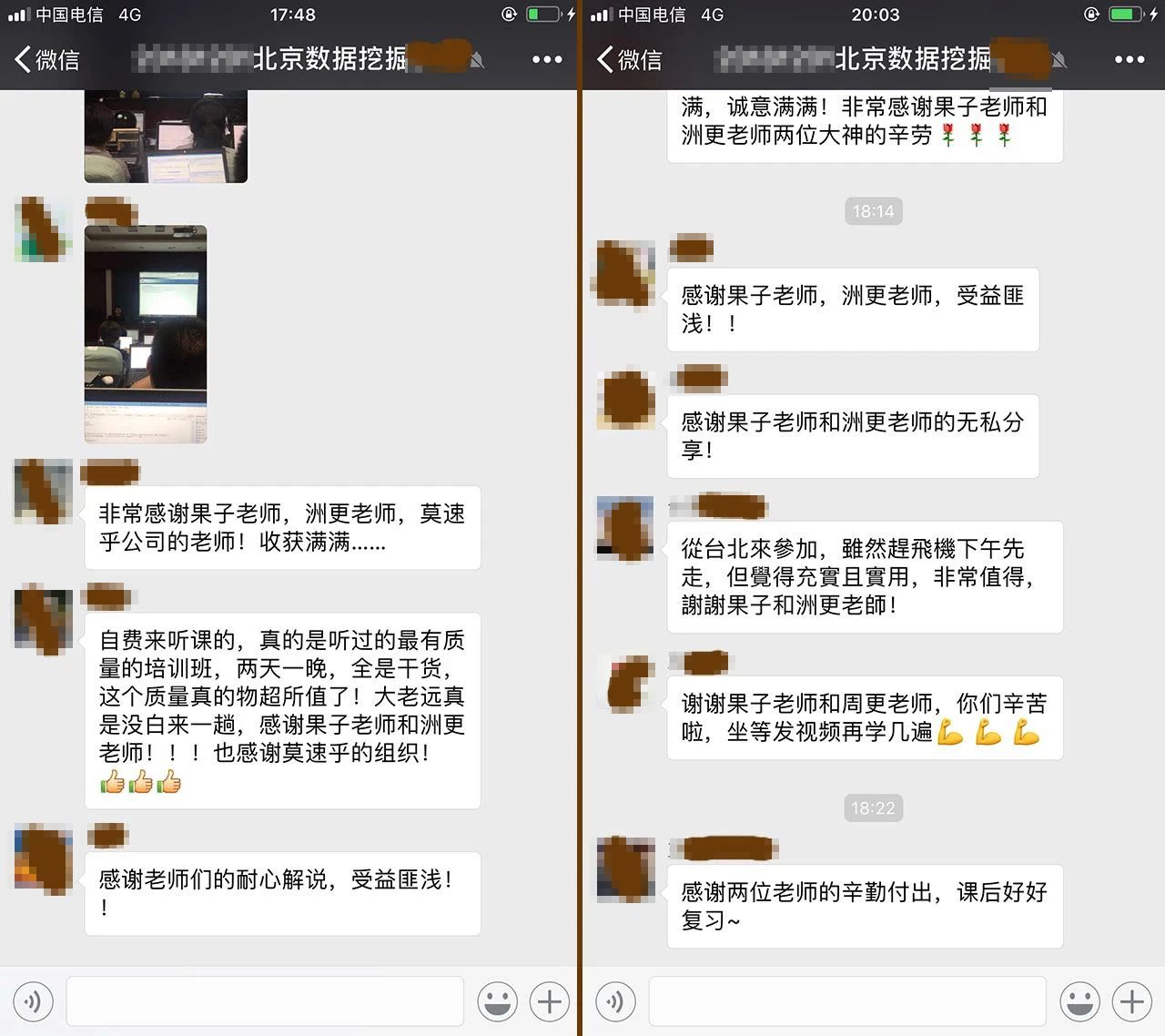
这是一份带有诚意且注重实战的数据挖掘课程。我们的目标是:一次学习,不再报班。

主讲人介绍
果子老师(果子学生信作者,在站博士后),在生信方面具有丰富经验,本次进行两天一晚的高强度实操训练,目标是让大家一次学习不再报班。
作为临床科研工作者,深知无课题之苦,因此愿将所学知识和盘托出,没有隐藏。
致力于给非生信专业人员普及生物信息学,擅长各种组学的处理,且讲课诙谐幽默。
适合人群
广大临床/科研工作者及心有热血被困囚笼的研究生
课程安排
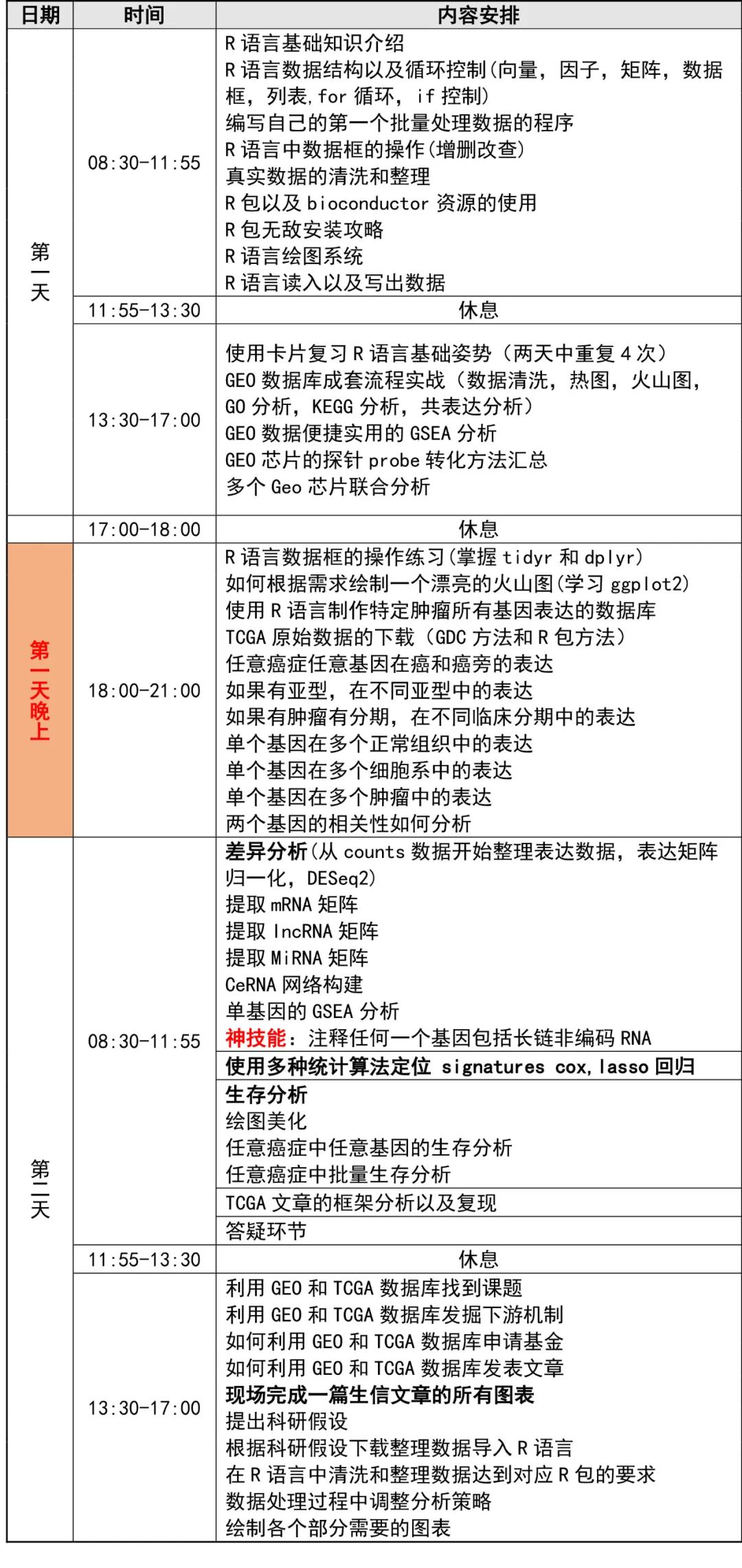
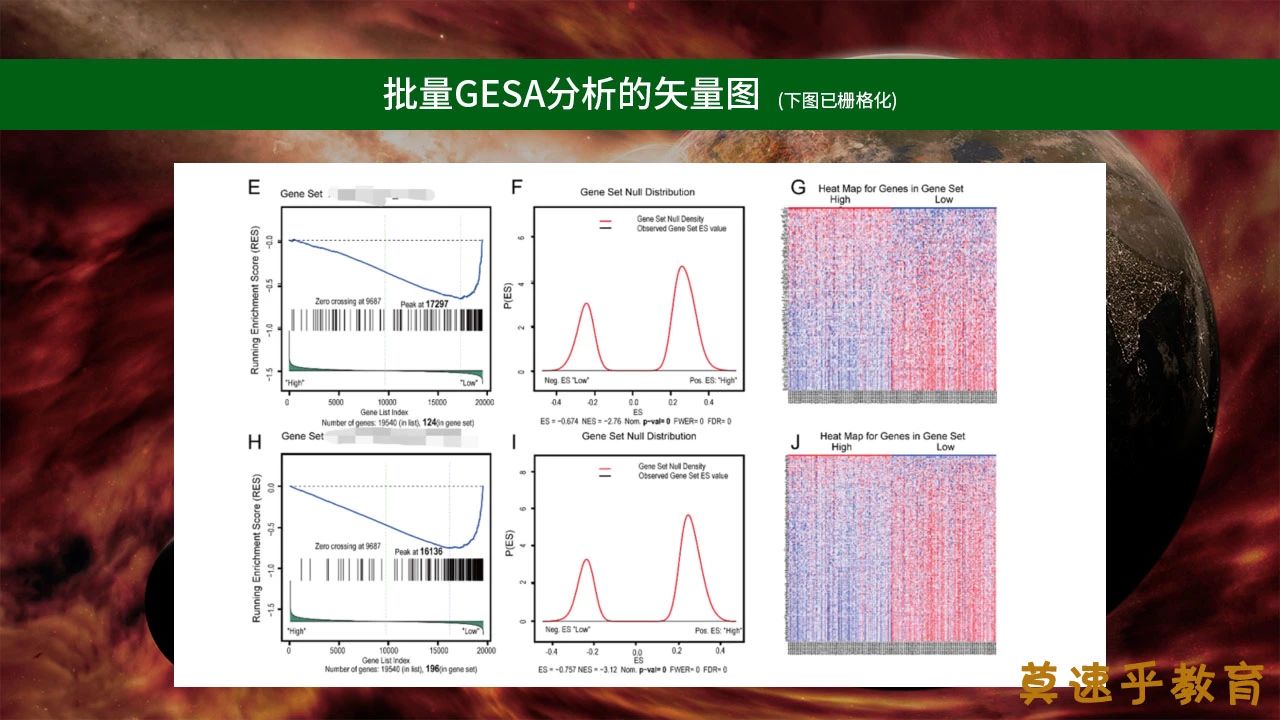
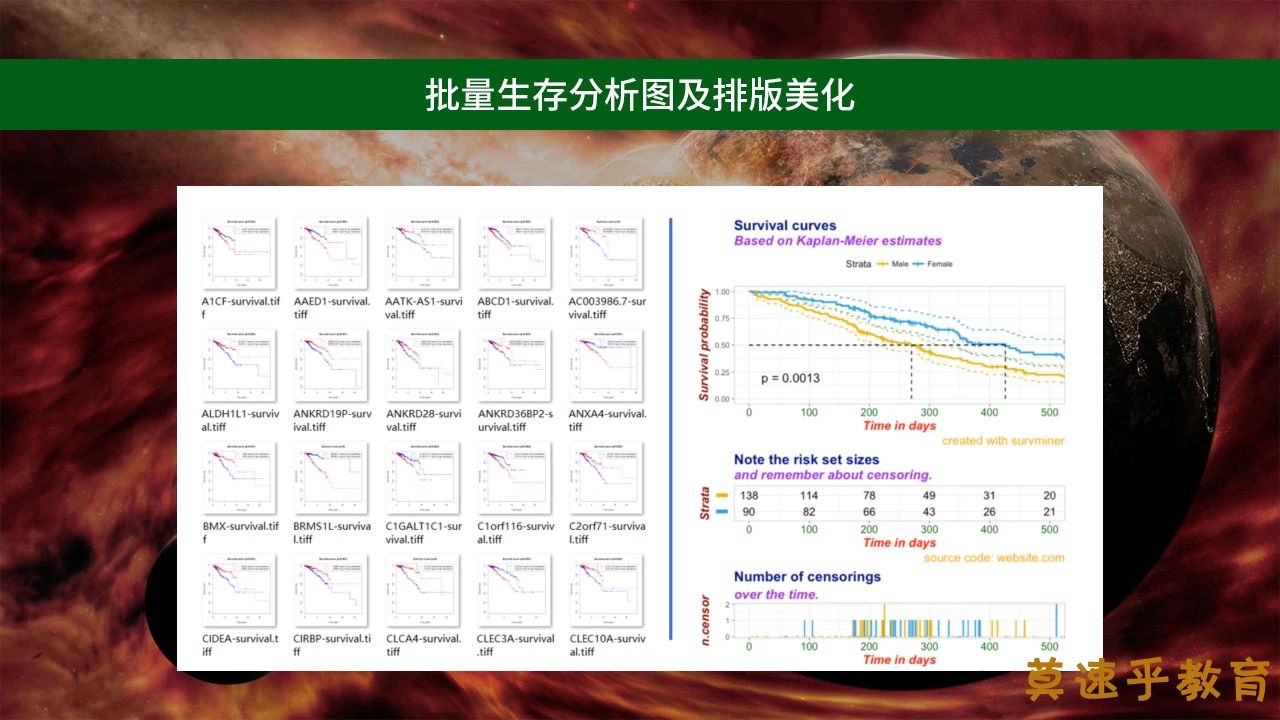
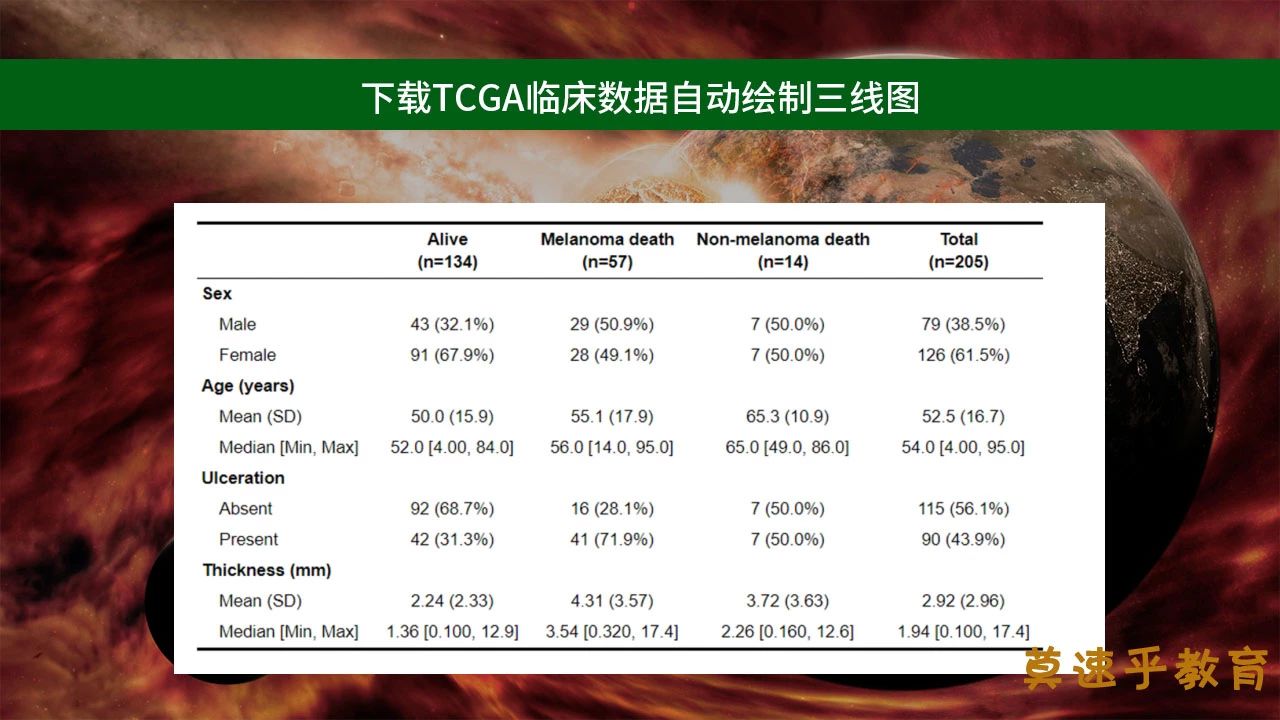
时间地点
第三十一期 2021/10/16-17 (会议时间两天&一晚)
使用腾讯会议客户端进行在线讲课(非录播)
由于疫情原因不能开展线下班
注册费用
3400元/人
报名付费成功后,课前发培训需要应用到的软件与安装包,并且指导安装
两天集中网络授课,互动性好;
可开具会务费、数据分析费、测序费、检测费等发票;
课后赠送课堂同步视频,可无限重复回放;
参加培训的学员可通过微信群继续和老师交流,长期获得答疑机会;
报名咨询
177-1782-7961 何老师 ,4000-709-739 客服热线
缴费账号
方法一:企业银行转账
收款单位:上海荆麦信息科技中心
开户行:中国建设银行上海泗泾支行
银行账号:3100 1983 0100 5002 2781(转账去空格)
少数单位需银行行号:105290080036
备注:写明姓名+数据挖掘 便于核实
方法二:支付宝转账
支付宝收款账户:mosuhu@163.com
请核对户名:上海莫速乎教育投资有限公司
备注:写明姓名+数据挖掘 便于核实
方法三:信用卡或公务卡支付
微信或支付宝扫描二维码支付,通过信用卡/公务卡扣款
报名后发送付款二维码
付款备注:写明姓名+数据挖掘 便于核实
报名方式
加微信发送以下信息:
姓名;邮箱;手机;单位;发票信息(发票抬头、税号、开票内容、邮寄地址);在哪里看到学习班信息,以免弄错。
如有多人参加,逐个说明即可。
任何疑问,也可直接拨打会务组电话4000-709-739或177-1782-7961(何老师)
其他培训
更多培训班信息,请扫码关注公众号:

 微信公众号
微信公众号