来源:微信公众号“智慧交通”

当我们开车的时候,会不断地关注周边的环境,以确保自身及他人的安全。我们会特别注意潜在障碍物的位置,无论是其他车辆、行人还是路上的物体。同样,当我们开发自动驾驶汽车系统时,让其能准确探测到障碍物也是非常关键的,因为它加强了汽车对周围环境的理解。路上行驶的其他车辆,是障碍物检测的重中之重,因为它们很可能是我们车道上或邻近车道上最大的物体,因此其潜在危险性也最大。
从传统的计算机视觉技术到深度学习技术,各种障碍检测技术得到了很大的发展。在本算法中,我们使用一种传统的计算机视觉技术,称为定向梯度(HOG)的直方图,结合一种称为支持向量机(SVM)的机器学习算法,构建了一种车辆检测器。
数据集
Udacity提供了一个均衡的数据集,具有以下特征:
9000张车辆图像
9000张非车辆图像
所有图像均为64x64
数据集来自GTI车辆图像数据库、KITTI Vision基准测试库以及从项目视频本身提取的示例。后者要大得多,但没有用于这本算法。然而,这些示例在将来会非常有用,特别是当我们计划使用深度学习建立分类器时。您可以从下面的数据集中看到一个图像示例:
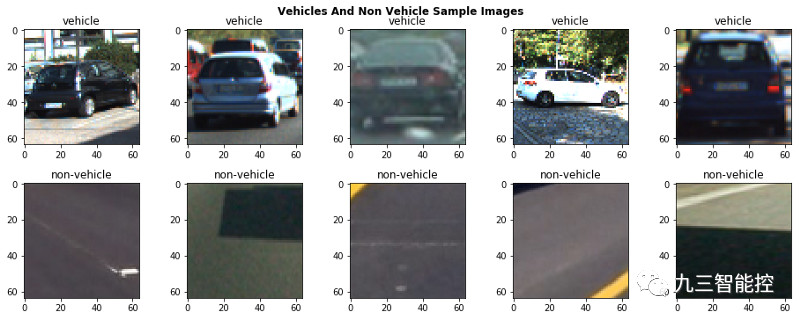
我们可以清楚地看到车辆和非车辆的图像。非车辆图像往往是道路的其他元素,如沥青,道路标志或路面等。大多数图像中,车辆位于道路正中,但在不同的方向,这对我们训练模型很有好处。此外,图像集中还包含了不同的汽车类型和颜色,以及照明条件等。
梯度方向直方图(HOG)
Navneet Dalal和Bill Triggs在他们的论文《 Histogram of Oriented Gradients For Human Detection》中,展示了利用HOG进行物体检测所取得的惊人效果。
我们首先在RGB图像上探索了HOG算法,参数配置如下:
方位数(用o表示)
每个单元像素(用px/c表示)
每个块的单元格最初固定在2(用c/bk表示)。下图是RGB格式的车辆图像样本结果:

纯粹的来看,它看起来像一个HOG配置:
我们可以利用HOG制造出车辆最独特的坡度。前期,我们未对每一块不同的单元进行测试,所以现在尝试测试一下。
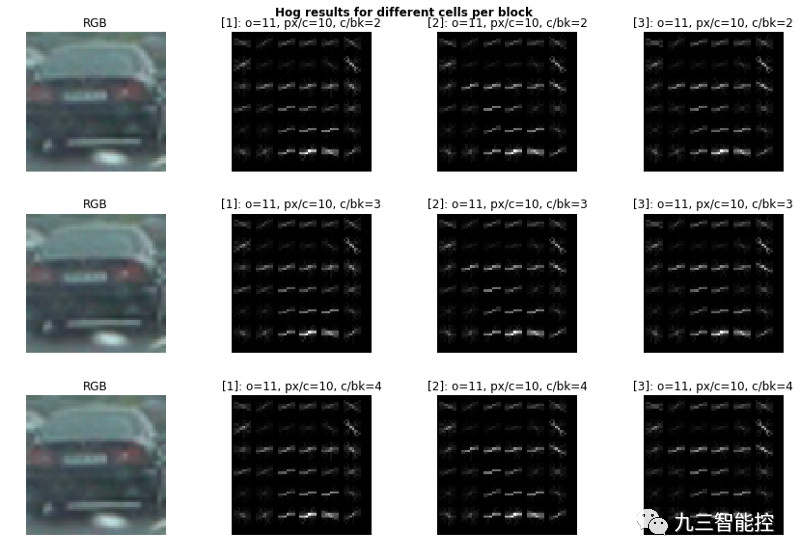
我们在视觉上没有注意到明显的差别。理想情况下,我们希望减少特征空间,以便更快地进行计算。我们现在只需要3个单元格。
色彩空间
现在,我们必须为我们的配置探索最合适的色彩空间,因为我们跨越3个RGB通道的HOG特征看起来太相似了,因此我们感觉我们没有生成足够多变化的特征。
我们在多种颜色空间中生成以下输出:

对于一些颜色通道,很难解释HOG的结果。有趣的是,YUV、YCrCb和LAB中的第一个颜色通道似乎足以捕获我们正在寻找的渐变特征。在HSV和HLS中,值通道和亮度通道分别捕获了车辆最重要的特征。
为了证实我们的假设,让我们试着用一个不同的汽车图像:

这里有个问题:在一张较暗图像上,通道上传输最多光信息的HOG反而产生了不好的结果。因此,我们必须考虑到所有的颜色通道,以获取最多的功能。最后,我们的配置如下:
所有YCrCb通道的色彩空间
11的HOG朝向
每个单元格的HOG像素值为14
每个HOG块的单位数为2个
我们还将添加颜色信息,以增强我们的功能。为此,我们只需使用32个bins,在所有颜色通道上生成直方图,代码如下:
1def color_histogram(img, nbins=32, bins_range=(0, 256)):
2 """
3 Returns the histograms of the color image across all channels, as a concatenanted feature vector
4 """
5 # Compute the histogram of the color channels separately
6 channel1_hist = np.histogram(img[:,:,0], bins=nbins, range=bins_range)
7 channel2_hist = np.histogram(img[:,:,1], bins=nbins, range=bins_range)
8 channel3_hist = np.histogram(img[:,:,2], bins=nbins, range=bins_range)
9 # Concatenate the histograms into a single feature vector and return it
10 return np.concatenate((channel1_hist[0], channel2_hist[0], channel3_hist[0]))
分类器
分类器负责将我们提交的图像分类为车辆类或非车辆类。为此,我们必须采取以下步骤:
从数据集中加载图像
提取想要的特性
特征正则化
划分训练集和验证集
使用适当的参数构建一个分类器
训练分类器
如前一节所述,我们决定只保留一个特征:在YCrCb图像的Y通道上计算的HOG特征向量。
我们随机分割数据集,留下20%用于测试。此外,我们使用sklearn.preprocessing. StandardScaler 函数进行正则化。
我们没有足够的时间来试验许多的分类器,因此选择使用支持向量机(SVM),因为它们通常能与HOG进行较好的结合,从而用于物体检测。此外,我们使用了带有核rbf的SVC,因为它提供了最好的精度,但其比LinearSVC略慢。当我们在一系列图像上测试SVC时,使用rbf内核的检测能力要强得多,所以我们接受了这种折衷。
使用GridSearchCV函数得到了核类型(线性或rbf)、C(1,100, 1000, 1000)和gamma (auto, 0.01, 0.1, 1)之间的理想参数。最佳配置精度超过99%,参数如下:
kernel= rbf
C = 100
gamma = auto
滑动窗口
我们创建了多个维度的滑动窗口,范围从64x64到256x256像素,以测试图像与分类器,并只保留正向的预测。我们通常会将较大的窗口从屏幕底部滑动,因为这将对应于车辆看起来最大的位置。更小的窗口在屏幕上会滑得更高。此外,我们还可以配置单元格重叠,并将其设置为1,以实现最大覆盖(即每14个像素x尺度重叠,其中尺度1的最小窗口为64x64)。我们不再试图在y方向350像素以下(即屏幕上图像的更高部分)检测车辆。下图是重叠滑动窗口的例子,单元格重叠设置为4:
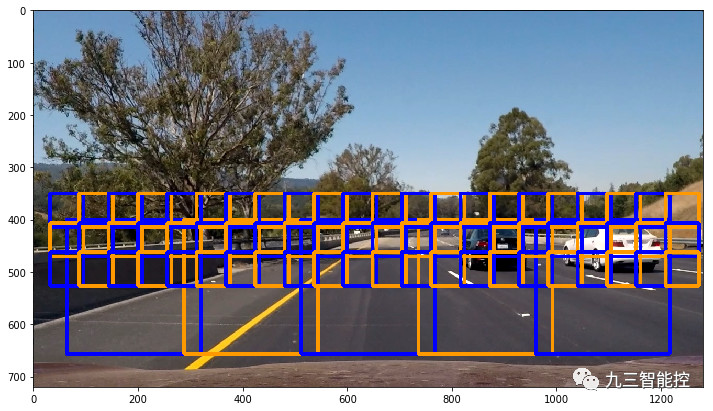
输热值图与阙值
分类器有时会对实际上不是车辆的图像进行错误分类。为了避免在视频中高亮显示,我们利用了多尺寸滑动窗口所产生的冗余,并计算了分类器预测的车辆在图像中出现的所有窗口的次数。我们首先使用scipy.ndimage标记具有重叠窗口的对象。然后,我们通过确定被检测对象能够容纳的最小边界框来提取每个标签的位置。
我们设置了一个阙值,并只保留图像中满足阈值的区域。通过实验,我们发现阈值设置为4,就足以获得可靠的结果。下图说明了热图和阈值工作原理:
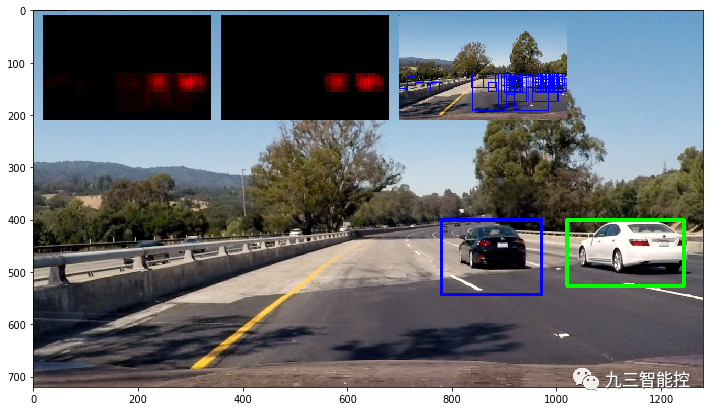
第一个min热图表示原始分类器的原始检测结果,而第二个则显示阈值区域,其中红色的强度随着重叠窗口数量的增加而增加。右边的最后一张min图片显示了我们的分类器预测车辆的所有窗口。在这个例子中,我们实际上使用了LinearSVC,但它比rbf SVC更容易出错。
帧聚合
为了进一步加强我们的算法,我们决定平滑所有检测到的窗口为n帧。为此,我们在帧(n-1)*f+1到n*f之间积累所有检测到的窗口,其中n是一个正标量,表示我们所在的帧组。我们已经创建了以下类来封装检测对象:
1class DetectedObject:
2 """3 The DetectedObject class encapsulates information about an object identified by our detector4 """5 def __init__(self, bounding_box, img_patch, frame_nb):6 self.bounding_box = bounding_box7 self.img_patch = img_patch 8 self.frame_nb = frame_nb9 self.centroid = (int((bounding_box[0][0] + bounding_box[1][0]) / 2), int((bounding_box[0][1] + bounding_box[1][1]) / 2))10 self.similar_objects = []
每当我们在组中的当前或下一个帧上检测到一个新对象时,我们都会检查过去是否检测到类似的对象,如果是这样,我们会追加类似的对象,从而在多个帧上增加这个对象的计数。在第n*f帧中,我们只保留检测到的数量超过m的对象(及其关联的边界框),从而在管道中实现某种双重过滤(第一个过滤是重叠边界框的数目的阈值)。
在下图中,你可以看到,在一秒左右的时间内,我们有一个单独的边界框覆盖了两辆车。但随即,两辆车被分别开,并单独用边框标识。

原文链接:
https://towardsdatascience.com/teaching-cars-to-see-vehicle-detection-using-machine-learning-and-computer-vision-54628888079a
 微信公众号
微信公众号