来源:微信公众号“GitChat技术杂谈”
作者:刘宇达
背景
当前,人工智能是下一代信息技术的核心和焦点,而无人配送则是人工智能典型的落地场景,因为完成无人配送需要自动驾驶技术、机器人技术、视觉分析、自然语言理解、机器学习、运筹优化等一系列创新技术的高度集成。目前,美团的日订单数量已经超过 2000 万单,在人力有限的情况下,对无人配送就有着非常迫切的需求。美团无人配送团队已经自主研发两款适应不同业务场景的无人车产品,其中一款适用于室内外道路的小型低速无人车,还有一款室外运输的中型无人车。
目标检测和语义分隔技术简介
目标检测
目标检测是在一幅图片中找到目标物体,给出目标的类别和位置,如下图所示:
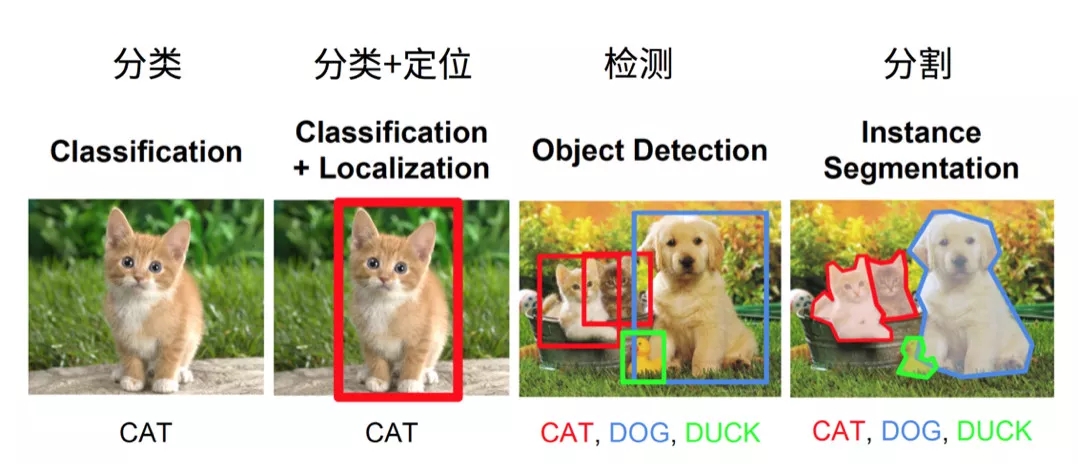
在 2014 年以前,目标检测通常采用比较传统的方法,先想办法生成一些候选框,然后提取出每个框的特征,例如 HOG,最后通过一个分类器来确认这个框是否是目标物体。而生成候选框的方式也有很多种,比如用不同大小的预选框在图片中滑动,或者像 Selective Search[1] 算法一样,可以根据图片本身的纹理等特征生成一些候选框。但是自 2013 年以来,随着深度学习相关技术的发展,不断有新的模型出现,可以实现端到端的训练检测网络,并且效果比传统方法有了显著的提高。
目标检测的发展脉络如下图所示:
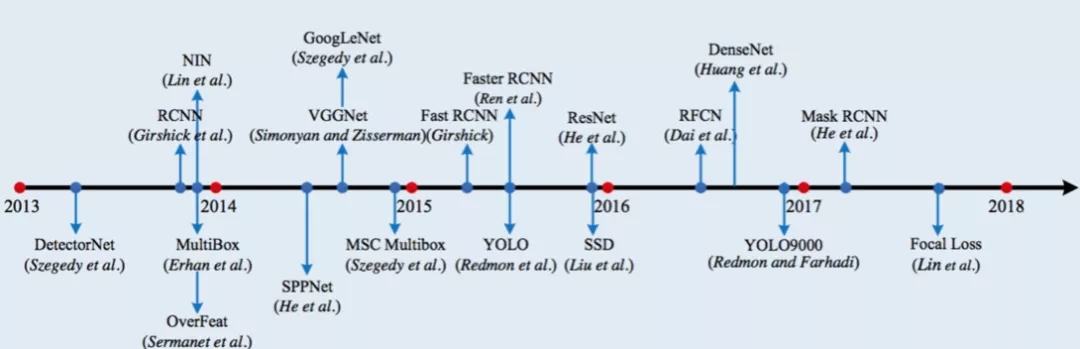
目标检测方法分为 One-Stage(一步检测算法) 和 Two-Stage(两步检测算法) 两种。
两步检测算法是把整个检测过程分为两个步骤,第一步提取一些可能包含目标的候选框,第二步再从这些候选框中找出具体的目标并微调候选框。
而一步检测算法则是省略了这个过程,直接在原始图片中预测每个目标的类别和位置。
两步检测最经典的就是 Faster-RCNN[4] 三部曲。
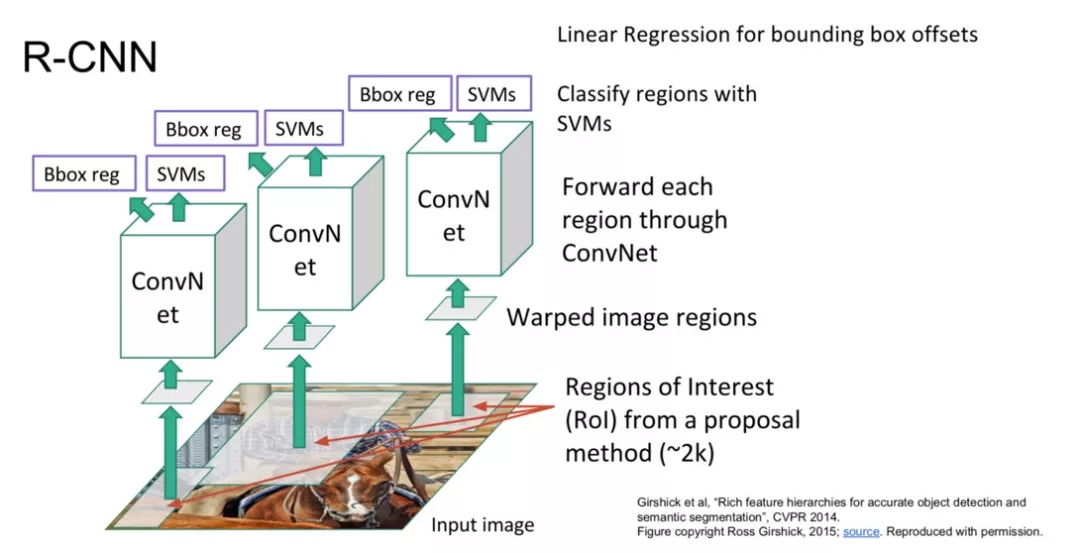
R-CNN[2] 是比较早期提出用深度学习解决检测的模型。思路是先用 Selective Search 算法提取一定数量的候选区域,然后对于每个候选区域使用 CNN 提取特征,最后在提出的特征后面接一个回归和 SVM 分类,分别预测目标物体的位置和类别。R-CNN 的优点是使用了 CNN 提出的特征,效果比较好。当然,缺点也很明显,整个过程分成了好几步,无法完整的训练,另外由于每个候选框提特征是独立计算的,整个过程包含了大量的冗余计算。
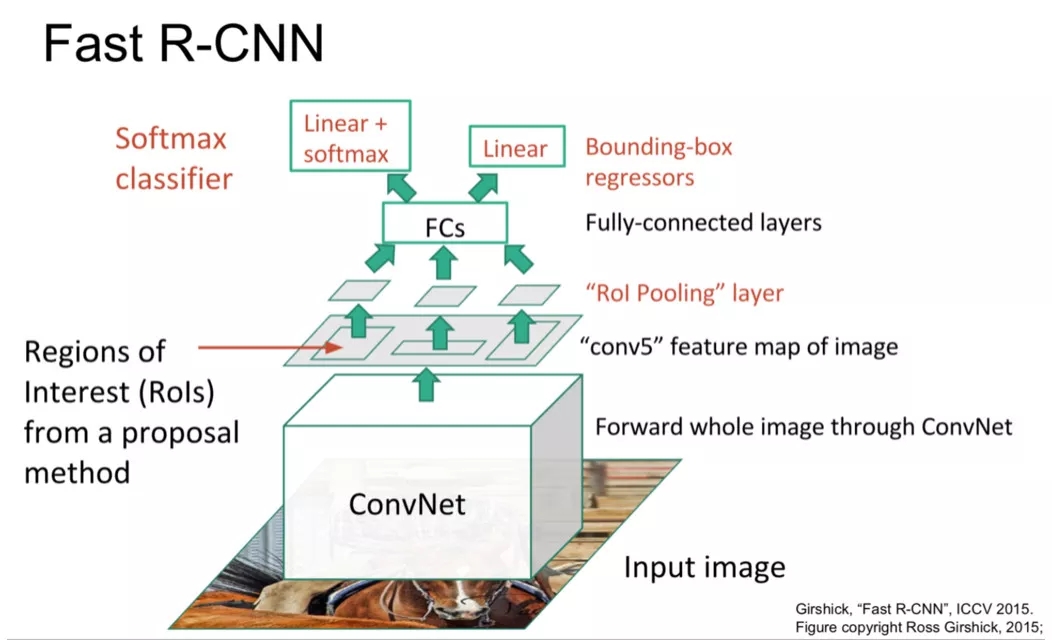
Fast-RCNN[3] 是在此基础上的一个改进版本,主要解决了提取特征时冗余计算的问题。首先对整张图片做卷积,提取特征得到一层 Feature Map,然后再提取每个候选框的特征时直接在这个 Feature Map 上面提取特征。但是每个候选框的尺寸是不一样的,而后面做分类和回归时要求特征必须定长。为了解决这个问题 Fast-RCNN 中提出了 Roi-Pooling 层,可以对不同大小的区域提取出固定维度的特征,使得后面的分类和回归可以正常运行。这个模型整体减少了大量的冗余计算,提高了整个模型的运行速度。
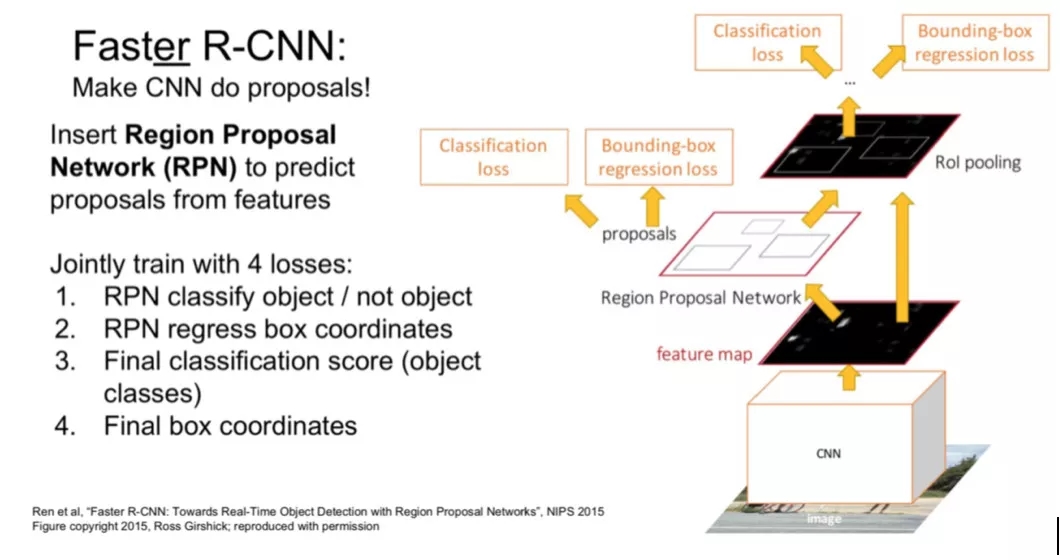
Faster-RCNN[4] 是三部曲的最后一步。Fast-RCNN 存在的问题是:提取候选区域仍然是使用的 Selective Search 算法,打乱了整个模型的连续性。Faster-RCNN 为了改进这点提出了 RPN 结构,RPN 可以在 Feature Map 的每个位置提取很多不同尺寸、不同形状的候选框,也叫 Anchor。每个 Anchor 后会跟一个二值分类,来判断这个 Anchor 是否是背景,并接一个回归对位置进行微调。具体的类别和位置在网络尾端还会进一步调整。至此,整个目标检测过程都可以实现端到端的进行训练。
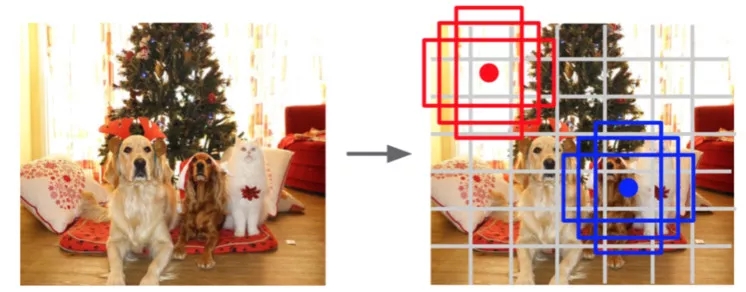
在一步检测中,比较经典的是 YOLO[5] 和 SSD[6] 模型。这里介绍下 YOLO 算法。首先将图片划分为 NxN 的方格,每个方格预测 C 个类别概率,表示某类目标中心落在这个方格的概率,并且预测 B 组位置信息,包含 4 个坐标和 1 个置信度。整个网络输出 NxNx(5xB+C) 的 Tensor。YOLO 的优点是:省略两步检测中提区域的步骤,所以速度会比较快,但是它对于密集小物体的识别很不好。后续的 YOLOv2[7] 和 YOLOv3[8] 都对此做出了很多的改进。
分割
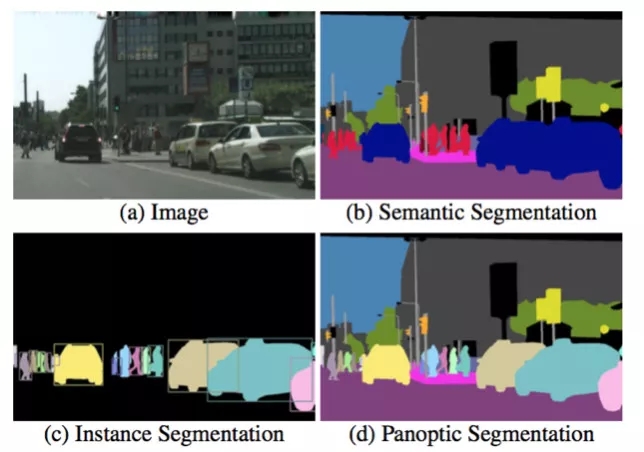
分割,是一个对图片中的像素进行分类的问题。分割最初分为语义分割和实例分割。语义分割是对图片中每一个像素都要给出一个类别,例如地面、树、车、人等。而实例分割则和目标检测比较像,但是实例分割是要给出每个目标的所有像素,并且同一种类别不同目标要给出不同的 ID,即可以将每个目标清晰的区分开。
今年,有人研究将语义分割和实例分割统一在一起,称为全景分割,如下图所示:
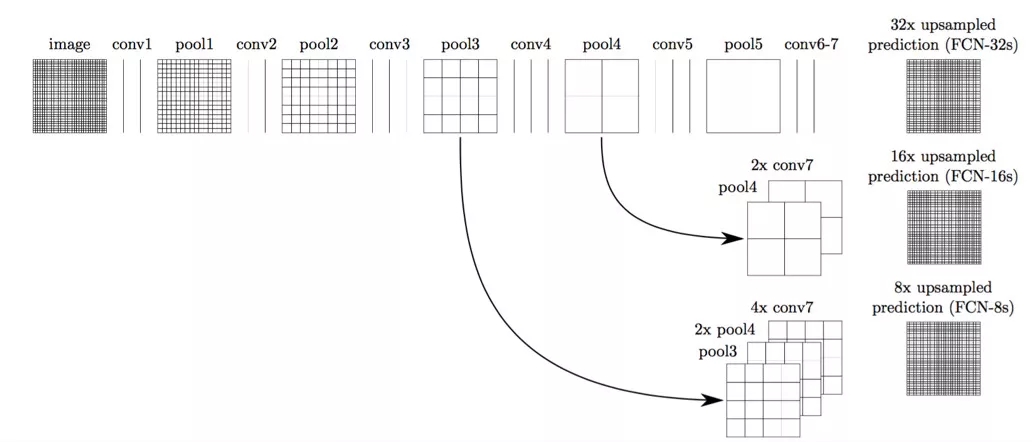
在无人驾驶中应用比较多的是语义分割。例如路面分割、人行横道分割等等。语义分割比较早期和经典的模型是 FCN[9]。FCN 有几个比较经典的改进,首先是用全卷积层替换了全连接层,其次是卷积之后的小分辨率 Feature Map 经过上层采样,再得到原分辨率大小的结果,最后 FCN 使用了跨层连接的方式。跨层连接可以将高层的语义特征和底层的位置特征较好地结合在一起,使得分割的结果更为准确。FCN 结构图如下所示:
目前很多主流的分割模型准确率都比较高,但是帧率会比较低。而无人驾驶的应用场景中模型必须实时,尤其是高速场景下,对模型的速度要求更高。目前美团使用的是改进版的 ICNet[10],既保证了模型的运行速度,又保证了模型的准确率。下图是一些经典分割模型的时间和准确率对比图:
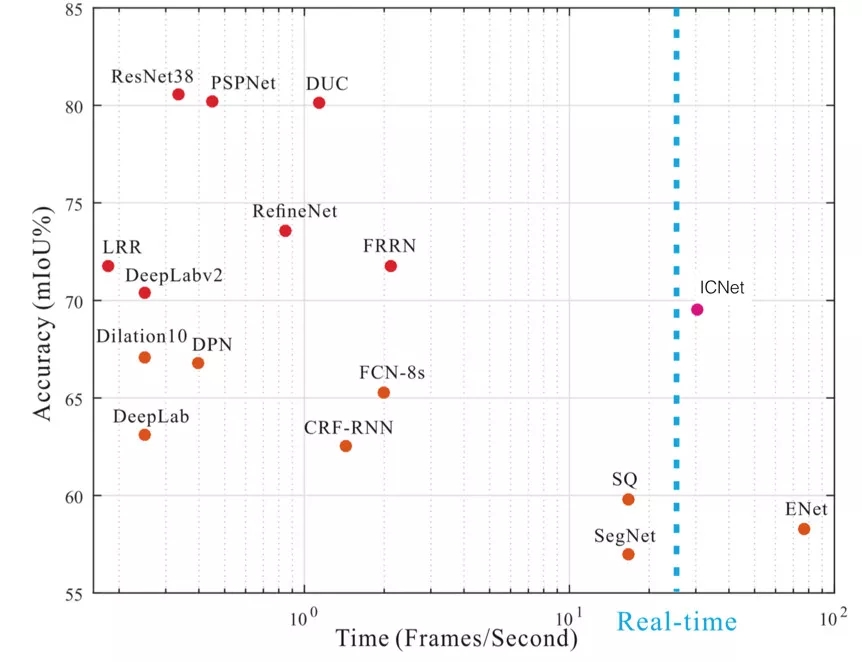
无人驾驶相关介绍
传感器
在无人驾驶中,车辆在行驶时需要实时地去感知周围的环境,包括行驶在哪里、周围有什么障碍物、当前交通信号怎样等等。就像我们人类通过眼睛去观察世界,无人车也需要这样一种 “眼睛”,这就是传感器。传感器有很多种,例如激光雷达、摄像头、超声波等等。每种传感器都有自己的特点:摄像头可以包含丰富的颜色信息,可以识别各种精细的类别,但是在黑暗中无法使用;激光可以在黑暗或强光中使用,但是雨天无法正常工作。目前不存在一种传感器可以满足不同的使用场景,所以目前业界通常会通过传感器融合的方式来提高准确率,也能够弥补缺点。各种传感器的特点可以查看下图:
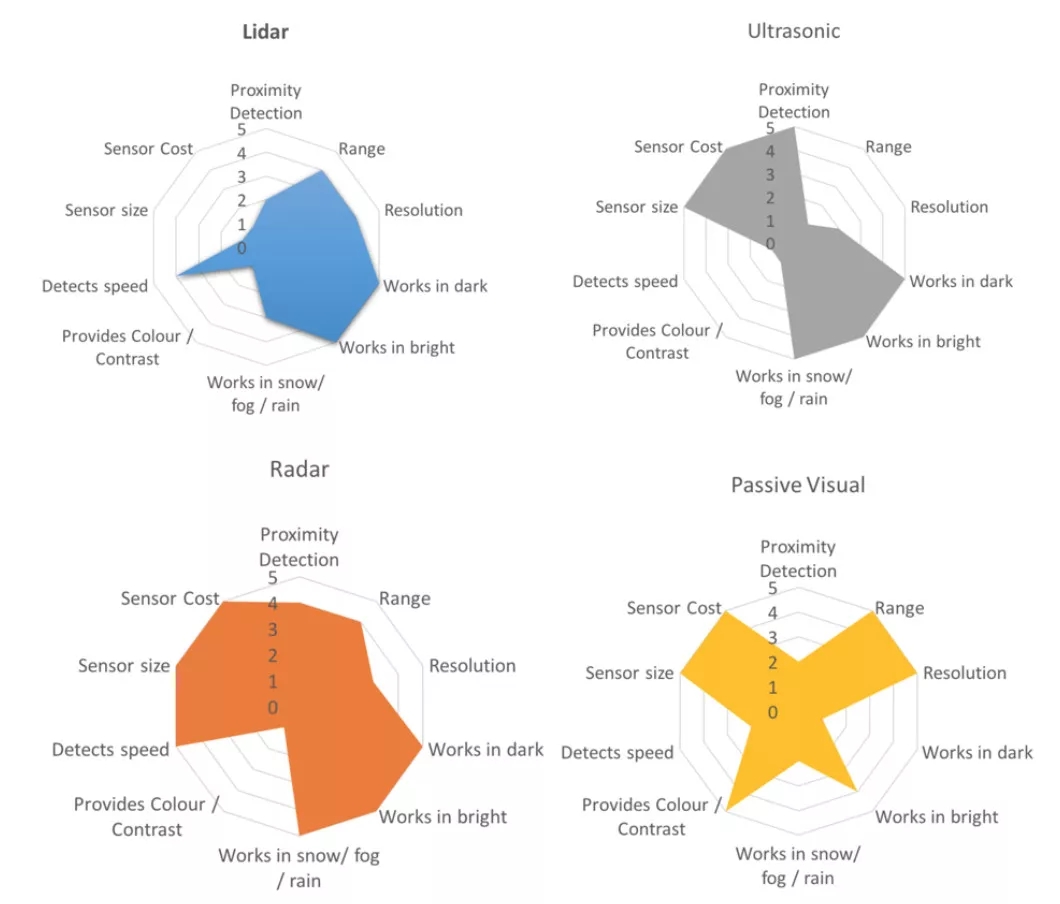
不同的传感器的数据格式有很大差别,所以也会有专门针对某种传感器数据设计的算法。例如有专门针对激光点云设计的障碍物检测模型VoxelNet。
目标检测
由于摄像头数据(图片)包含丰富的颜色信息,所以对于精细的障碍物类别识别、信号灯检测、车道线检测、交通标志检测等问题就需要依赖计算机视觉技术。无人驾驶中的目标检测与学术界中标准的目标检测问题有一个很大的区别,就是距离。无人车在行驶时只知道前面有一个障碍物是没有意义的,还需要知道这个障碍物的距离,或者说需要知道这个障碍物的 3D 坐标,这样在做决策规划时,才可以知道要用怎样的行驶路线来避开这些障碍物。这个问题对于激光的障碍物检测来说很容易,因为激光本身就包含距离信息,但是想只凭借图片信息去计算距离难度比较高。
分割
分割技术在无人驾驶中比较主要的应用就是可行驶区域识别。可行驶区域可以定义成机动车行驶区域,或者当前车道区域等。由于这种区域通常是不规则多边形,所以分割是一种较好的解决办法。与检测相同的是,这里的分割同样需要计算这个区域的三维坐标。如果我们分割的目标都是地面的话,就可以使用“距离估计”中第5种方式获得精确的三维空间中的区域坐标,这种应用在未来对无人驾驶有着巨大的意义,因为现在的无人驾驶都是基于高精地图,而这种基于可行驶区域的方案是一种脱离高精地图的方案。当然这种方案目前也只能在限定场景下应用,还不是很成熟。

距离估计
对于距离信息的计算有多种计算方式:
激光测距
原理是根据激光反射回的时间计算距离。这种方式计算出的距离是最准的,但是计算的输出频率依赖于激光本身的频率,一般激光是 10Hz。
单目深度估计
原理是输入是单目相机的图片,然后用深度估计的 CNN 模型进行预测,输出每个像素点的深度。这种方式优点是频率可以较高,缺点是估出的深度误差比较大。
结构光测距
原理是相机发出一种独特结构的结构光,根据返回的光的偏振等特点,计算每个像素点的距离。这种方式主要缺点是结构光受自然光影响较大,所以在室外难以使用。
双目测距
原理是根据两个镜头看到的微小差别,根据两个镜头之间的距离,计算物体的距离。这种方式缺点是计算远处物体的距离误差较大。
根据相机内参计算,原理跟小孔成像类似。图片中的每个点可以根据相机内参转化为空间中的一条线,所以对于固定高度的一个平面,可以求交点计算距离。通常应用时固定平面使用地面,即我们可以知道图片中每个地面上的点的精确距离。这种计算方式在相机内参准确的情况下精度极高,但是只能针对固定高度的平面。
业界相关进展
目前业界开源的解决方案中比较成熟的是百度的 Apollo[11],包含了改进的 ROS 底层系统,以及无人驾驶中各个模块的实现。Apollo 中视觉方案的距离计算非常有意思,这里简单介绍一下。Apollo 使用一个模型去预测 2D 图片中物体的框,以及物体实际的在三维空间中的长宽高和朝向。当我们知道一个物体在三维空间中的位置和姿态(长宽高和朝向)时,我们可以根据相机内参,计算这个物体投影到图片中的所在区域。那么如果我们知道物体在图像中的区域和在三维空间中的姿态,我们如何计算三维位置呢?可以根据近大远小的特点,去二分物体离我们的距离。这就是 Apollo 中视觉方案的距离计算方法。
除了 Apollo 之外,业界开源解决方案还有 Autoware[12]。虽然 Autoware 并没有 Apollo 火热,但是也给我们提供了一些解决问题的思路。Autoware 的视觉方案通过激光与摄像头联合标定的方式将每个激光点转换到图像之中,并进一步根据 2D 检测结果,知道哪些激光点打到了这个物体上,由于激光点的三维坐标是已知的,就可以计算出这个物体的距离。
美团自研算法
美团的自研算法参考了 Autoware 的这种解决思路,并做了很多改进。同样先将激光点转换到图片当中,这样我们就知道每个激光点打到了哪里。在得到每个 2D 框中的激光点之后,我们需要做一步聚类操作,这样可以过滤掉打到背景上的点,于是我们就得到了打到这个物体上的激光点(参看下图红点)。然后在三维空间中,我们可以拟合这些激光点,得到一个三维框,包含了物体准确的位置信息。这种方法计算出的三维框相对比较准确,但缺点是对于远处较小的物体,由于打到的激光点太少了,难以拟合出合适的结果。具体效果可以参看下图:

总结
本文从计算机视觉方向的检测和分割出发,介绍了相关算法原理,以及其在无人驾驶中的实际应用。之后介绍了距离估计的一些算法,以及业界的一些视觉解决方案。
目前业界主流的的无人车障碍物感知是依赖于激光的,视觉方案相对还不是很成熟。但是我们仍然比较看好视觉方案,因为其成本低,并且可以减轻对高精地图的依赖。
参考文献
[1] Uijlings, Jasper RR, et al. "Selective search for object recognition." International journal of computer vision 104.2 (2013): 154-171.
[2] Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
[3] Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE international conference on computer vision. 2015.
[4] Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems. 2015.
[5] Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[6] Liu, Wei, et al. "Ssd: Single shot multibox detector." European conference on computer vision. Springer, Cham, 2016.
[7] Redmon, Joseph, and Ali Farhadi. "YOLO9000: better, faster, stronger." arXiv preprint (2017).
[8] Redmon, Joseph, and Ali Farhadi. "Yolov3: An incremental improvement." arXiv preprint arXiv:1804.02767 (2018).
[9] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[10] Zhao, Hengshuang, et al. "Icnet for real-time semantic segmentation on high-resolution images." arXiv preprint arXiv:1704.08545 (2017).
[11] https://github.com/ApolloAuto/apollo
[12] https://github.com/CPFL/Autoware
分割
分割,是一个对图片中的像素进行分类的问题。分割最初分为语义分割和实例分割。语义分割是对图片中每一个像素都要给出一个类别,例如地面、树、车、人等。而实例分割则和目标检测比较像,但是实例分割是要给出每个目标的所有像素,并且同一种类别不同目标要给出不同的 ID,即可以将每个目标清晰的区分开。
今年,有人研究将语义分割和实例分割统一在一起,称为全景分割,如下图所示:
 微信公众号
微信公众号