来源:微信公众号“科赛Kesci”
基于中文维基,构建知识图谱,寻找15万个词向量之间的运算关系,云脑机器学习实战训练营第二课带来「中文维基知识图谱构建挑战」。
我们请导师对第二波挑战中的作品做了一波点评,来扒一扒别人家的作业强在哪。
作品链接如下,你可点击阅读原文,或复制链接至浏览器,登录科赛 Kesci查看
https://www.kesci.com/apps/home/project/5a1d0e90d0178b641c3bb8d5
项目介绍
将所有的中文维基作为语料,并将维基条目名作为字典进行向量化,词向量用于将词或短语映射到一个固定维度的向量上,将词汇和短语用离散的数字表示能够在一些任务(如寻找近似词)上相较于传统方法取得显著的优势。
相较于英文语料,中文语料需要进行额外的分词和繁简转换步骤,经过预处理后,使用千万条级维基的正文来生成训练数据,并使用训练数据的一部分作为测试数据集。完成模型的训练后,可以得到了近15万个词向量,根据向量之间的距离可以构建基于词语关系的知识图谱,从而进行基于词汇的文本语义分析。
数据预处理
1.分解数据
将整个xml文件按page分开,每个page对应一个xml文件,存放在几个文件夹内,同时生成对应的索引文件(id_title_map.csv)
2.清理数据
将page分类,包括:重定向页面,帮助页面,词条页面(上述数据集中的ID_Title_Map_Pruned.csv,格式为folderID:pageID,title. eg:1:13,数学)
3.抽取关系链接图
记录图的节点信息,即重定向点(指同一个实体有多个表述方式),入度和出度信息
4.抽取文本
对文本的清理工作,包括分词,去标点空格,英文字母处理等等,得到干净的文本,放到一个txt(pagesTextCleanAnchorID.txt)中,一行代表一个page的文本,同时生成对应索引文件(pagesTextCleanAnchorID_Index.txt)
5.扩充词条
上一步得到得txt每一行包含词条数目大于1的内容中的词条文本替换成AnchorID,得到上述数据集中的pagesTextCleanAnchorID_tittle_extend.txt,eg:"数学 是 利用 符号语言 研究 326166 130077130654 以及...",原文本为“数学是利用符号语言研究数量、结构、变化以及..."
6.处理title
将page内容中包含title本身的汉字替换成titleID(由于title本质上也是anchor,所以这里也可以当作anchorID来理解)。
7.仅留anchor
将page内容中的汉字都去掉,仅留下anchorID,得到上述数据集中的WikiDict_pagesOnlyAnchorID_tittle_extend.txt
导师点评
这位同学做了比较详细的数据处理流程的描述。在这个项目中,虽然大部分的预处理工作我们已经做好,但是,理解数据处理的流程也非常关键。在实际的工作中,我们所得到的原始数据与最终模型的需求之间,往往有较大的差距。随着工作的进行,经常需要回过头来对数据处理的流程进行调整修补。这样,有一份细致的数据处理文档就非常重要,不但方便了后面项目成员的理解,同时回顾自己的工作时也比较省力。
模型包的选择
class gensim.models.word2vec.
Word2Vec(sentences=None, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=\, iter=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000, compute_loss=False)
sg 决定运行的模型算法. 默认(sg=0), 使用CBOW. 否则 (sg=1), 使用skip-gram.
size 特征的维度,也就是一个单词向量的纬度。本实验建议为64(但我平时做实验一般取得128/256).
window 句子中当前单词和被预测单词的最大距离.
alpha 初始学习率 (会随着训练的进行线性减小到min_alpha).
seed 随机数生成种子.
min_count 忽略出现次数小于这个数目的单词.
max_vocab_size 最单词数,是为了限制单词太大占内存,假如实际单词超过这个数字,去掉出现次数最小的。一千万单词大概需要1GB内存
sample 高频词是否进行亚采样(downsampled)的阈值.默认为1e-3, 范围(0, 1e-5).
workers 使用多少个线程训练模型(在多核机器上跑的更快~,我下面的参数设置就是机器有几核,咱就开几个线程).
hs 如果为1, 会使用hierarchical softmax进行模型训练. 如果设为0 (默认), 并且negative为非零数, 会使用negative sampling.
negative 如果>0, 使用negative sampling, 这个整数代表多少“noise words”会被删除 (通常设为5-20之间的数值). 默认为5. 设为0, 不使用negative samping.
cbow_mean 如果为0, 使用上下文单词向量的和. 如果为1 (默认), 使用上下文单词向量的平均值. 只在cbow被使用的时候生效
hashfxn 用来随机初始化权值的hash function,用于增强学习的再现性.
iter 迭代次数,默认为5.
sorted_vocab 如果为1 (默认), 为单词设置index之前先按单词出现频率降序排列单词.
batch_words 传到线程的数据batch大小. 默认为10000.
导师点评
这次作业中,很多同学选择了gensim包作为模型的实现。这是一个做word2vec比较受欢迎的选择,没有什么问题。但是选择现成的包时,需要比较好地去理解哪些参数可以调,这些参数的含义是怎样的,以加深对于模型的理解。这位同学做得比较好的地方是她很详细地列出了这些参数的说明,为后面模型的应用和调参打下了比较好的基础。
模型的训练
导师点评
这位同学记录了模型训练所花费的时间。这里建议最好能够把模型训练过程中的loss下降的情况也能够打印出来。通过观察模型训练的过程,可以帮助我们找到一些线索,如果我们在前面处理过程中有一些缺陷也容易发现。
模型效果的评估
王力宏 & 李玟 : 0.946530
王力宏 & 蕭亞軒 : 0.942849
王力宏 & 張惠妹 : 0.939810
王力宏 & 周华健 : 0.938387
王力宏 & 孙燕姿 : 0.937986
王力宏 & 王菲 : 0.928927
王力宏 & 辛曉琪 : 0.926367
王力宏 & 陶喆 : 0.925689
王力宏 & 張韶涵 : 0.925686
王力宏 & 范瑋琪 : 0.925610
蔡依林 & 蕭亞軒 : 0.948877
蔡依林 & 林宥嘉 : 0.932087
蔡依林 & 潘瑋柏 : 0.927098
蔡依林 & 張惠妹 : 0.919681
蔡依林 & 王心凌 : 0.915485
蔡依林 & 孙燕姿 : 0.906726
蔡依林 & 田馥甄 : 0.904995
蔡依林 & 羅志祥 : 0.904079
蔡依林 & 五月天 : 0.903583
蔡依林 & 黃麗玲 : 0.903006
歌手 & 創作歌手 : 0.894803
歌手 & 台灣歌手列表 : 0.858475
歌手 & 女歌手 : 0.856085
歌手 & 流行樂團 : 0.827676
歌手 & 歌手 : 0.818265
歌手 & 男歌手 : 0.809164
歌手 & 創作型 : 0.807691
歌手 & 安室奈美惠 : 0.799534
歌手 & 男子音乐组合 : 0.799381
歌手 & 平井堅 : 0.792444
文言文 & 官話白話文 : 0.919003
文言文 & 文言文 : 0.908606
文言文 & 漢文 : 0.881737
文言文 & 文言 : 0.880541
文言文 & 漢文 : 0.859746
文言文 & 喃字 : 0.841082
文言文 & 喃字 : 0.839109
文言文 & 汉字 : 0.833915
文言文 & 书面语 : 0.831962
文言文 & 白話 : 0.826447
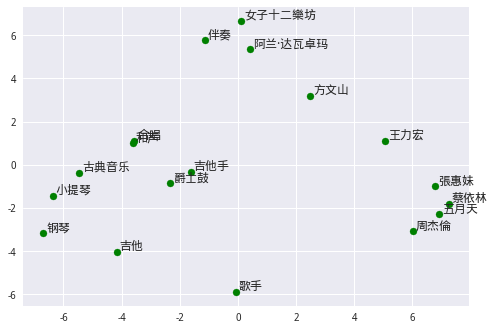
导师点评
对于word2vec效果的直观评估上,这位同学主要做了两件事。首先,打印了与某些词汇最相似的若干词汇出来,比如与“王力宏”最相似的词,主要都是一些歌手的名字,这也是比较make sense的。
其次,她做了可视化处理,在二维空间里直观地展示出词与词之间的相对位置关系。从图上也可以看到,乐器、歌手都相对集中地聚集到一些,显示它们在语义上的相似性。对于可视化来说,首先要做的处理是降维,不熟悉的同学,可以参考一下这个项目的做法。
这位同学还观察到一个点,通过word2vec模型,我们很容易找到在语义环境下比较“相似”的词对,但这不意味着它们之间是同义词,有时候也可能是反义词,像“加法”和“减法”,或者“文言文”与“官话白话文”。这是比较难处理的情况,后续还需要做些情感方面的分析。
手工模型实现

 微信公众号
微信公众号