刚刚给海尔寄去合作的合同,小编终于松了口气。这个项目中实验室主要负责机器人对于人的(动作)行为的理解。为什么机器人要能够理解人的动作(行为)呢?比如对于一款照顾小朋友的服务型机器人,只有知道小朋友是否跌倒了,是否想要喝水,是否走向危险的地方,这样才能更好的照顾小朋友。
对于机器人该如何判断一个人的动作(行为)呢?让我们一起学习动作(行为)识别吧!
背景介绍
我们要判断一个人的动作,自然不能单从一张静态的图片来考量,所以动作识别指的是判断一段视频中人的行为的类别(Human Action Recognition)。尽管目前在图像分类上深度学习发展迅速,如ImageNet,但是对于视频的分析和理解还差很多。
目前动作识别的难点主要是:
类内和类间差异, 同样一个动作,不同人的表现可能有极大的差异。
环境差异, 遮挡、多视角、光照、低分辨率、动态背景。
时间变化, 人在执行动作时的速度变化很大,很难确定动作的起始点,从而在对视频提取特征表示动作时影响最大。
缺乏标注良好的大的数据集。
算法速度,缺乏实际应用良好的高效算法。

目前在该领域最常用的数据库有UCF101,UCF Sports,JHMDB,Sub-JHMDB,Sports1M,HMDB,Hollywood2Tubes,DALY,Kinetics。
UCF101:包含13,320个视频,101种动作类别,例如:滑雪,篮球扣篮,冲浪。
JHMDB:包含928个视频,21中动作类别,例如:坐,笑,运球。
Sub-JHMDB:包含316个视频,12种动作类别,例如:抓,高尔夫,投掷橄榄球,走路。
UCF Sports:包含150个视频,10种运动类别,例如:滑板,骑马,走路。
Sports1M:来源于Youtube,包含1,133,158个视频,487种动作,例如:骑车,瑜伽,放风筝。
Hollywood2Tubes:包含1,707个视频,动作类别有:与另一个人打架,吃饭,从车中出来。
HMDB:来源于Youtube,包含7,000视频,51种动作类别。
DALY:该数据集来源于Youtube中的日常生活的动作,包含3,600个视频,10种动作:刷牙,涂口红,打扫地板,刷洗窗户,喝水,折叠纺织品,熨烫,打电话,吹口琴,拍照/摄影。
Kinetics:2017年最新出品,来源于Youtube,包含500,000个视频,600种动作类别,例如:演奏一些乐器,握手,拥抱等等等等。

上图即为HMDB数据库中的51种动作类别。
方法概述
在深度学习还没有火起来之前,大多数的传统的动作识别的算法都可以分为三个步骤:
提取视频局部的高维的稠密的或稀疏的特征;
组合提取的特征形成对于视频级别的特征描述。该步骤的一个变体是使用BOF(bag-of-features)方法生成视频级别的特征编码;
利用一个分类器,如SVM或者RF,对bag-of-features的特征进行最终的预测。
再后来,人们对上述方法进行了改进。在第一步过程中,使用iDT(improved dense trajectories)特征来替代原有的特征。特征的设计非常关键,而2013年提出的iDT方法一直是深度学习来临之前该领域前效果最好,稳定性最好,可靠性最高的方法。但是该方法的速度贼慢。
在iDT提出后不久的2014年,两篇文章带来了两个重大突破。这两篇文章主要的区别是围绕时空信息的设计选择的不同。下面来看这两个方法。
方法1:Single Stream Network
来源:Large-scale Video Classification with Convolutional Neural Networks
作者使用预训练的二维的卷积神经网络,探寻了多种方式从连续帧中融合时序信息。
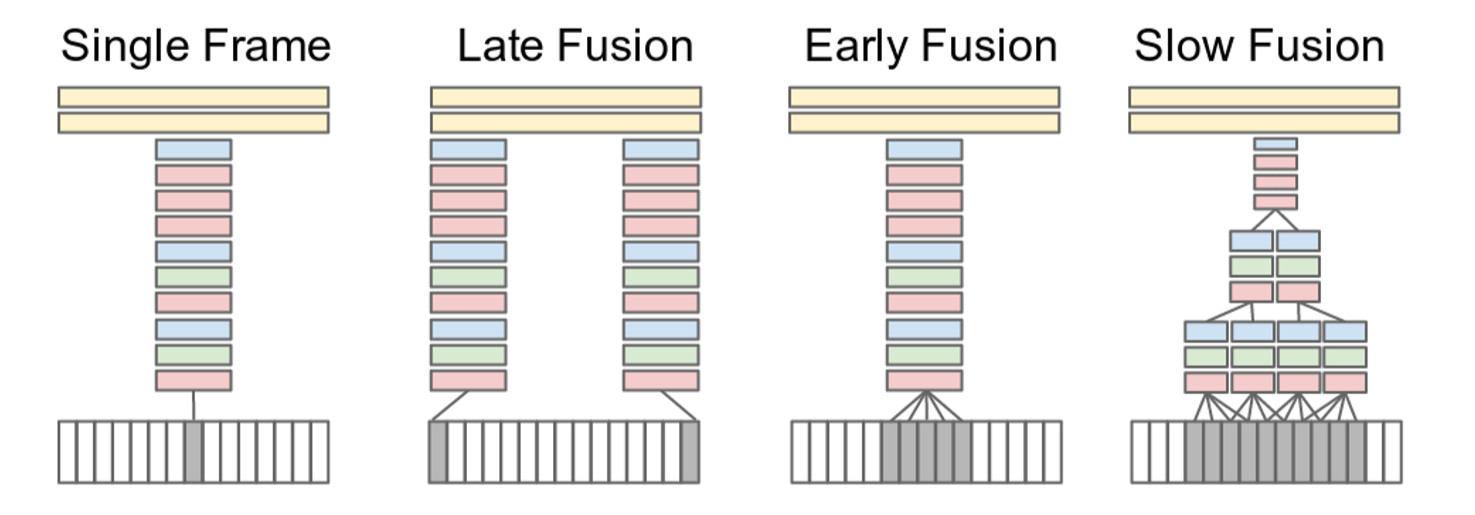
上图中红色,绿色,蓝色分别表示卷积层,Normalization和池化层。该图是作者提出的不同的关于时间信息的融合方案。本文做的是clip level video prediction, 即 treat every video as a bag of short, fixed sized clips. 在预测的时候,对一段video的所有clip预测结果做平均。主要思想是在CNN做图像分类的结构基础上探索了几种针对视频的结构,包括Single Frame(对一段clip只提取其中一帧),Late Fusion(将不同帧内容在第一个全连接层中融合),Early Fusion(将不同帧内容在第一层卷基层融合), Slow Fusion(将不同帧内容逐渐融合)。其中,对每列对应的网络,使用共同的网络结构和参数。其中每种操作的作用如下:
Single Frame:和普通的识别作用相同,主要是为了贡献整个识别的精度;
Late Fusion:第一个全连接层可以通过比较两个自网络的输出来计算全局动作特性;
Early Fusion:结合了整个时间窗口上像素级别的信息,可以允许网络精确地检测局部动作方向和速度;
Slow Fusion:Late Fusion和Early Fusion的结合,贯穿整个网络缓慢地融合时间信息。
由于在训练过程中因为比较耗时,作者提出了一种Multiresolution CNN,即将原有的178x178的帧分成两个89x89的stream,一个stream用于获取低分辨路的全局信息,另外一个stream用于获取中心区域的内容信息,最后将两个stream融合,这样的结构设计能够提高整个网络的效率。
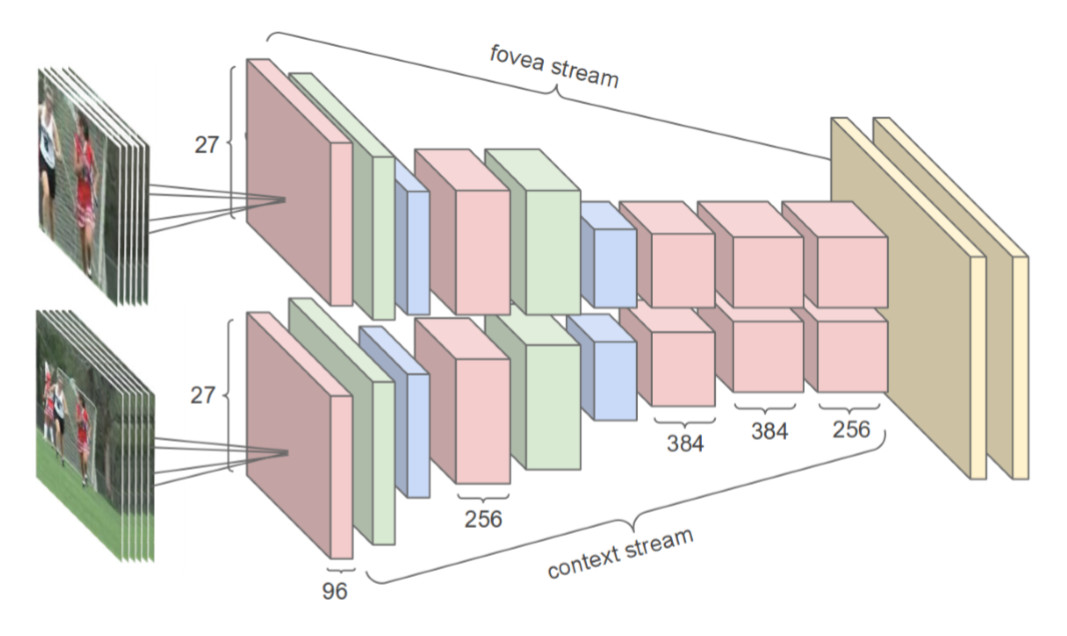
实际上这种方法在最终的效果上还没有当时使用手动特征的最好的结果好。问题在于:
学到的时空特征没有捕捉到运动特征。
数据集并不是那么多样化,对于特征的学习比较困难;
方法2:Two Stream Networks
来源:Two-Stream Convolutional Networks for Action Recognitionin Videos

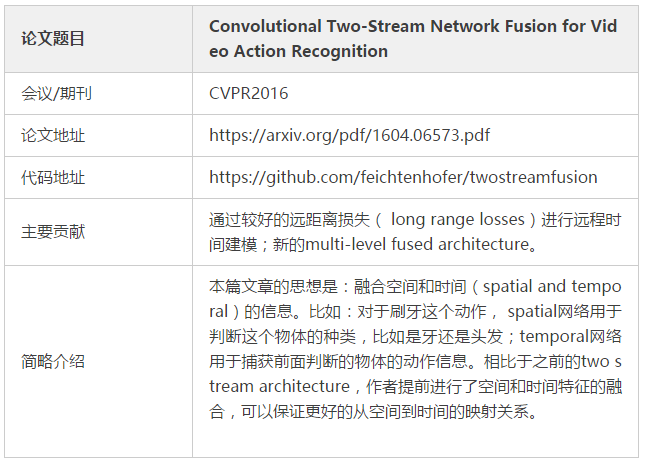
本篇作者实际上是对前面Single Stream Networ的改进。我们说过Single Stream Networ的问题是没有捕捉到运动特征(motion feature)。而这篇文章的网络引入了密集光流序列来对运动特征进行建模。因此提出了上图中Two Stream的网络结构。
基本原理为对视频序列中每两帧计算密集光流,得到密集光流序列(即temporal信息)。然后对于视频图像(spatial)和密集光流(temporal)分别训练CNN模型,两个分支的网络分别对动作的类别进行判断,最后直接对两个网络的class score进行fusion(包括直接平均和svm两种方法),得到最终的分类结果。对于两个分支使用了相同的2D CNN网络结构。
尽管相比于前一个方法,该方法捕获到了局部的动作信息,但是仍然有很多缺点:
对于视频级别的预测是通过对采样片段的预测求平均得到的,因此在学习的特征中仍然缺少长距离的时间信息;
由于训练clips是从视频中均匀采样得到的,所以它们存在假标签的问题;
训练中需要的密集光流序列需要提交手动处理得到并保存下来,因此并不是一个端到端的网络。
后来又有非常多的方法基本都是基于这两种方法进行改进的,如:
LRCN
C3D
Conv3D & Attention
TwoStreamFusion
TSN
ActionVlad
HiddenTwoStream
I3D
T3D
细致的总结一下,实际上这些论文都是基于以下模型设计实现的:
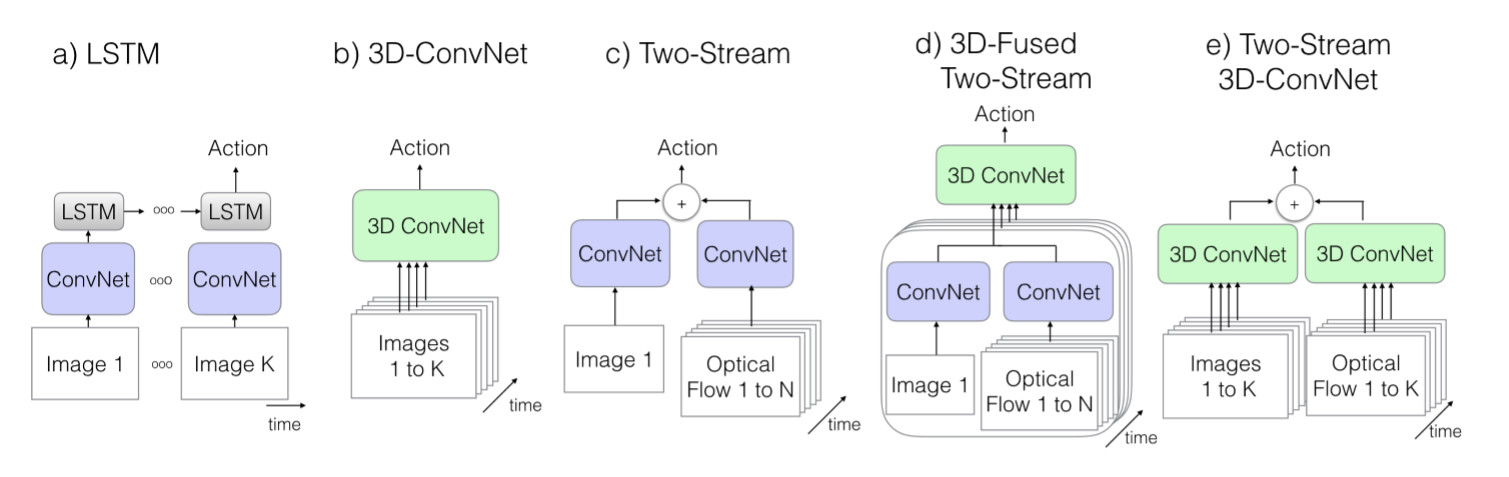
该图来自于Paper:Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
其中K表示一个视频的总帧数,N表示该视频中某子集(相邻的一些帧)的帧的数目。下面我们来介绍上面提到的九种模型。
LRCN:

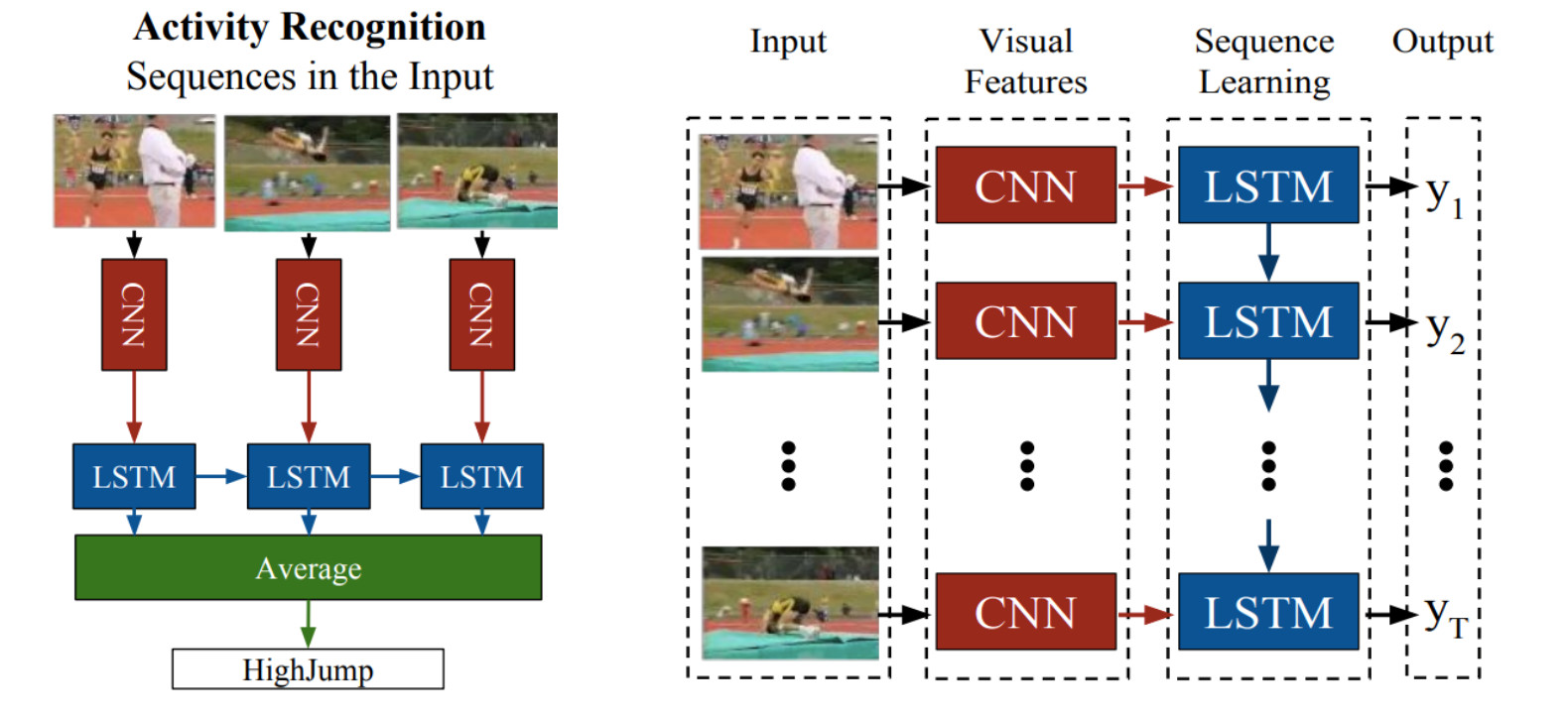
C3D:
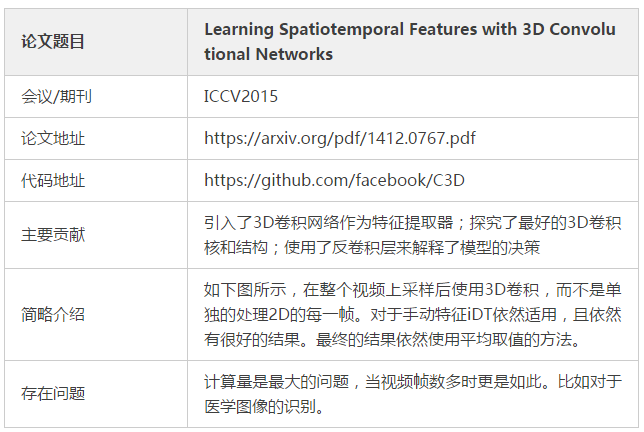

Conv3D & Attention:

注意力机制图示:
TwoStreamFusion:

上图为本文提出的两种融合时间和空间信息的策略。
TSN:


在上图中,对于所有的Snippets,ConvNets共享参数。
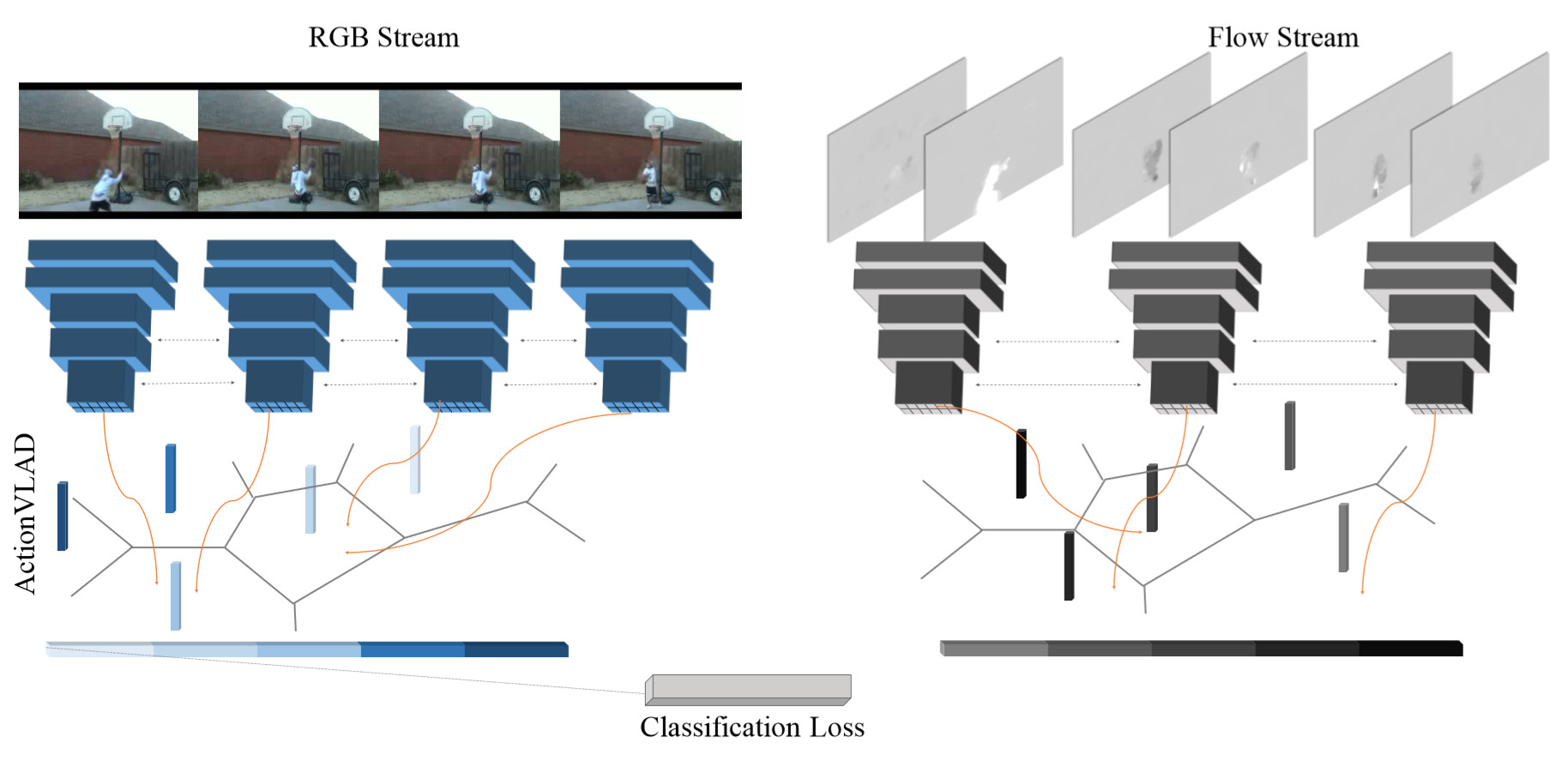
ActionVLAD:

该论文使用的网络结构也是基于two-stream类型的网络:
HiddenTwoStream:

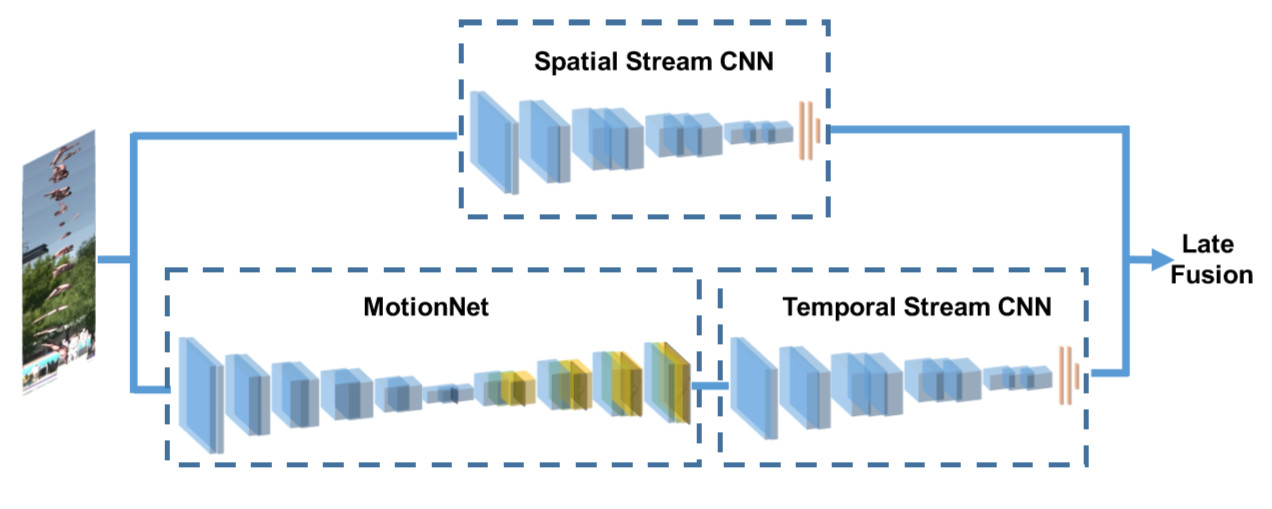
作者尝试了多种策略生成光流,并最终提出上图的网络结构。其中MotionNet用于生成光流,使用额外的多级损失(multi-level loss)来无监督的训练MotionNet。
I3D:

T3D:

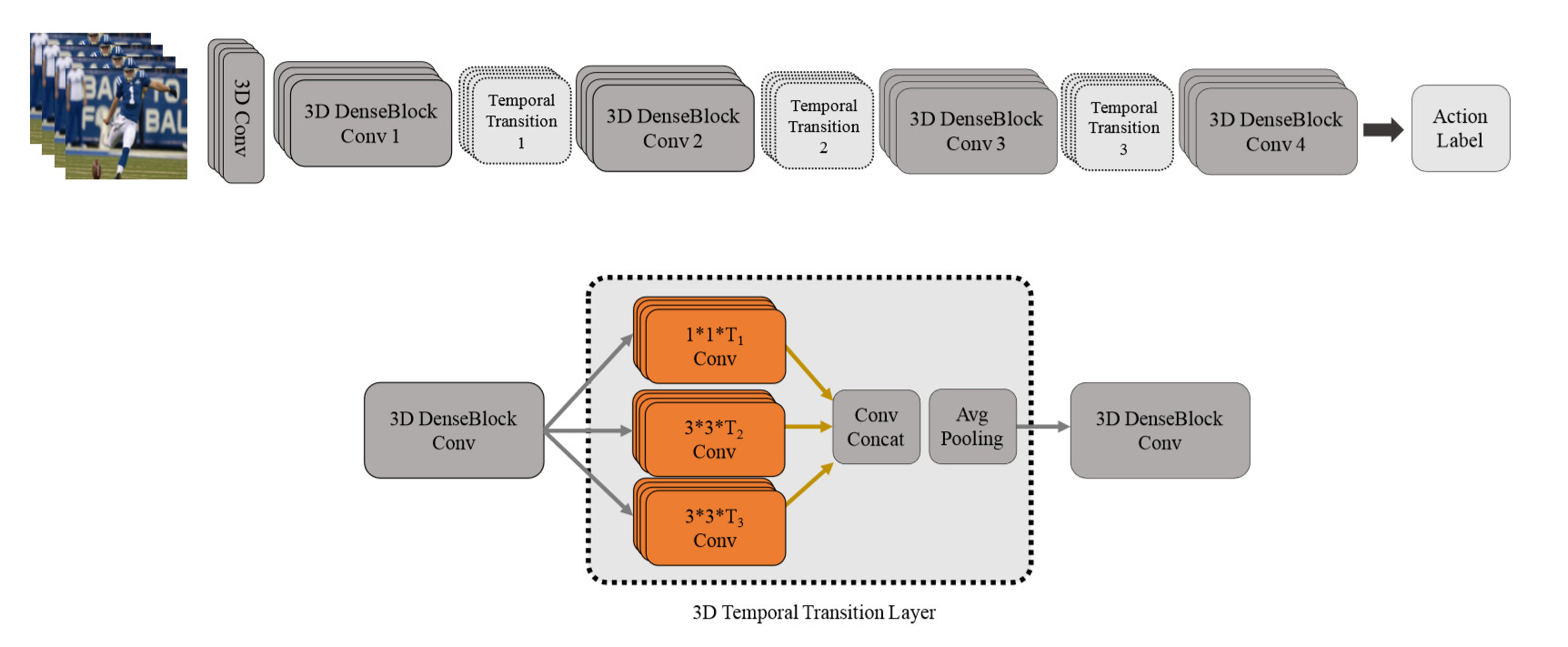
除此之外,作者还提出了新颖的将2D预训练网络迁移到3D网络的技术。
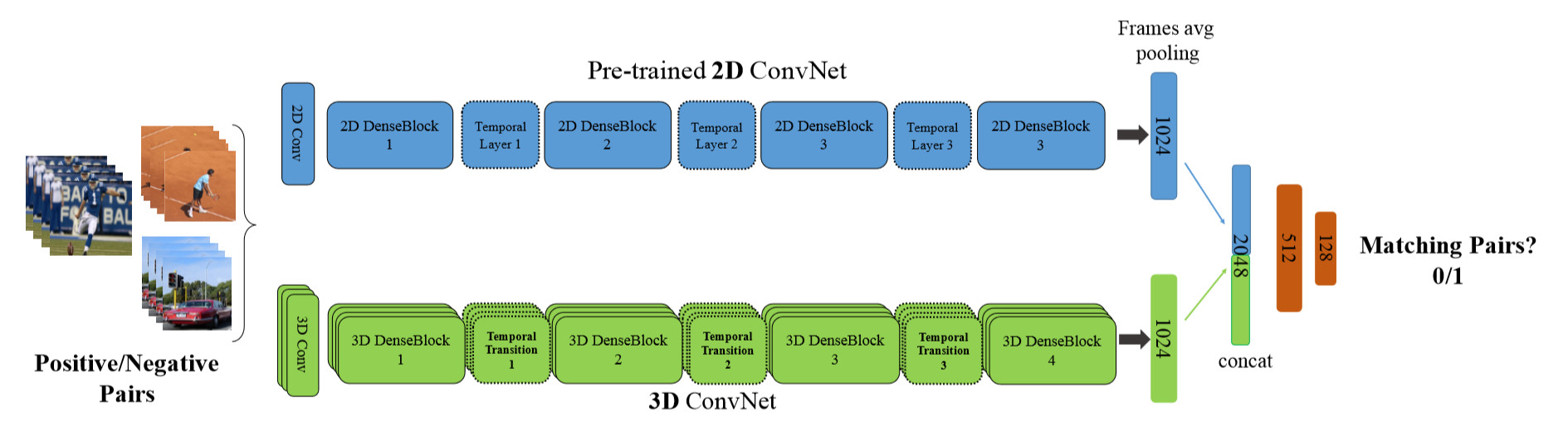
输入是一系列的帧和Clips对,这些对可能是同样的label,也可能是不同的label。在训练中预训练好的2D网络的参数固定,最终两者提取出来的特征表示会相近(实际上类似于对抗的思想)。本文最大的贡献就是该迁移方法的提出。
参考:
https://www.cnblogs.com/nowgood/p/actionrecognition.html
http://blog.qure.ai/notes/deep-learning-for-videos-action-recognition-review
https://blog.csdn.net/wzmsltw/article/details/70239000
https://github.com/NiyunZhou/The21-dayExpendables/issues/15
https://github.com/jinwchoi/awesome-action-recognition#action-recognition
 微信公众号
微信公众号