01社会计算概念的起源 社会计算(Social Computing)最早的是Schuler在1994年的时候发明的名词,我们就把1994年当做Social Computing元年,合理不合理?这该是大家唯一能取得的共识。否则每个人都会用概念往前推,有的可以推到Social Informatics才是开始,有的说Computational Simulation才是开始,甚至推到计算社会学(Computational Sociology)的社会模拟实验,依Castellani的说法那就可以推到1957年了。

九十年代、零零年代社会计算刚开始的时候定义其实跟今天有一点小小的落差,社会计算在那个时候讲的是什么?社交平台、BBS之类的软件,谈的是groupware, social software, mobile social software这些。这些软件沉积了很多大数据,企业家就很喜欢用大数据做各式各样的应用,所以那时候讲的主要都是怎么去发现一些社会需求,不管是社交需求,还是老板的分析需求。所以研究者会设计一些计算,从数据中发现规律,比如买尿片的顾客有相当的概率也会买啤酒。
后来Lugano指出,王飞跃等人强调了社会计算也该加入对社会现象及社会系统动态的研究。

与此同时,2009年 Science 杂志发表了Computational Social Science(计算社会科学)这篇文章,而且到现在这篇文章都很有名。它很短,正是因为很短,而且写得很简单,所以它更像是一个宣言。它不是一篇论文,是宣言,又发在Science上,所以影响力非常大。Computational Social Science 的概念跟2009年绑定在了一起,不是因为它真的来自于这一年,而是因为2009年是它推广开来的标志性时间。此前它大概至少有10来年的发展,才会有这篇宣言出来。所以,社会计算一方面有社会性增强计算科学的一面,到了今天尤其是从人、社交、社会的理解增强人工智能研究,已不限于social ware,而另一方面也包括了计算科学如何增强我们对人、社交与社会、经济、管理的研究。
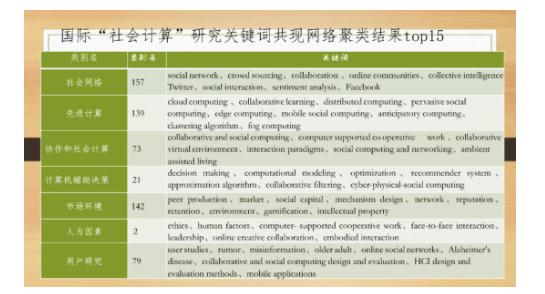
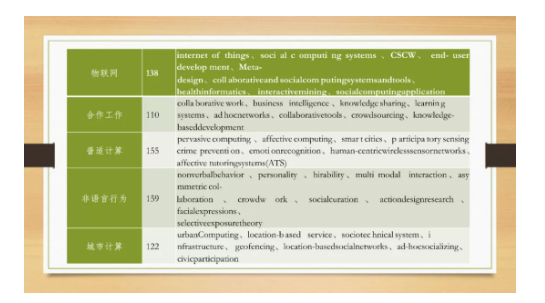
社会计算关注什么呢?浙江大学公共管理学院的黄萃教授,梳理了社会计算相关关键词,结果发现社会计算的概念内涵已经相当广泛,既包括计算的部分,也包括计算社会科学的部分。

为什么我今天谈方法论要从计算科学与社会科学的交互作用谈起?为了社会而有的计算,不管你是为了发展软件,还是发展AI新的技术,都需要知道人、社交与社会的内涵所以从方法论上来讲,它们两者是互补的,互为表里的,此先彼后,此后彼先,循环往复,相互作用的。今天我就从计算如何增强社会研究的这一端讲起。
我们发起了一个英文期刊Journal of Social Computing,编委大概是一半外国人一半中国人,一半文科一半理科组成,关注计算社会科学、复杂社会系统和人机交互等领域的最新研究成果。2020年10月发表了第一期,现在即将要出第三期。

02社会计算算什么
社会计算最简单概括,就是三种决策与行动加上三张网络。第一个叫做人的行动与决策与人际关系网络。其实这就是Computational Social Science 现在主要在做的工作,这个领域研究最多的主题就是社会网。

第二个是人工智能的「决策」与物联网loT。这里举一个汉服的例子。现在汉服流行什么?汉服有什么最新的设计形式?大家在言谈中表达的更喜欢汉成帝时候的服装,还是汉哀帝时候的服装?看到汉服圈子里大家在讨论这些问题,商家就能立刻来做一些相应的设计,这可能是未来十年内就会发生的场景。
在这个场景中间,AI普及的趋势和电脑普及的趋势是一样的。上世纪40年代刚刚有电脑的时候,只有英美的国防部才有。到60年代,终于有IBM360、370,有一些美国的大公司有。而到了现在,一个快递小哥恐怕都要两台以上电脑(智能手机)。AI在不久之前还只是阿里、腾讯等汇集算法和数据的公司有,而5年10年之后,我们每个人都会有。三五十年之后,每个人手上都有很多AI的应用在我们的智能设备中,就像现在几十个几百个APP在自己手上。
社会计算算什么的第三个是人机交互与人机共构网络。比如说,很多公司里头特别喜欢雇佣清华北大学生,雇来每一个人都是龙,但是凑成一个团队就是猫团队。但是你可能找一些普通高校进来的,结果做成一个团队却是高效团队。这其实是众愚成智还是众智成愚的问题。
这是社会计算和组织行为学都在做的研究:怎么形成一个高效团队,怎么形成一个创新型团队,机器在里头怎么扮演角色,人在里头这样扮演什么角色?人和人之间的关系网络会形成什么样的一个结构网络,最后一群人机互构成网络,一群人机如何协作?如何集体创新?最后形成一个什么样的形态,能够产生1+1>2、N个1加起来大于N的效果?
一方面这是群体决策,是群体智慧群体性的展现。另一方面这又是一个动态演化的过程,1+1>2就包含1+1在一起和它们的网络结构的共同演化,形成所谓的涌现现象,涌现出新智慧、新知识。复杂科学研究的就是这样演化、自组织涌现的系统现象。
看上图黄萃教授作的国际上social computing的主要研究议题,正好可以分成这三类。
03社会计算:从方法到方法论
在做研究的时候,有一种方法就是怎么样把无结构的电子印记数据,转化成将来能用的数据,这就叫做结构化过程。如果你要用Python去写针对自己需求的程序,比如像我的一个朋友唐锡晋教授团队,他们在做舆论极化研究的时候就不会用百度Senta这样的套装软件,而是把一个人回答问题的理性的程度分成10层。
他们会重新定义理性程度,然后来看这个人在争论转基因时,是理性的还是不理性的?又比如,图像识别是方法,声音识别是方法,多模态识别也是方法,但只有方法不够,更重要的是解决问题,例如如何用联邦学习算法,竟然可以不侵犯人家隐私去把两笔大数据给整合了。这些都是把无结构电子印迹数据转成能为我们所用的数据的方法。
还有一类方法,就是用这些数据解决我们面对议题的方法,如作预测模型可以用SVM、 随机森林,作聚类、排序可以用的双曲空间,把预测模型的「黑箱」拆出重要解释变量可以用Interpretable AI,如SHAP,作因果模型验证可以作logistic regression,作动态系统模型用ABM、MBM等等。
方法论就是如何组织这些型型色色的方法,共同解决一个研究的问题。
文科有道无术,理科有术无道
国内现在的情况是文理交融得还不太够,真正能够做到文理交融的非常少。经常出现的现象是我找一个工科的学生来一起做研究,他们的问题是手上十八般武艺,方法一大堆,你又会电钻,又会锯子,又会刨子,你可以帮我盖一栋房子么?他却跟我说房子是什么?然后开始跟他讲,你还需要读一个建筑学,跟你讲房子是什么,房子的蓝图要怎么画,蓝图变成房子的过程你要做些什么事。
文科就是特别喜欢做社会性研究的,但往往方法很弱。这不只是学生的问题,很多老师都是一样,他没有处理过大数据,却到处在讲大数据的未来、大数据对社会的影响、大数据怎么改变学术研究。手上一个工具都没有,去跟你讲空中楼阁。或者方法很弱,用的就是一些套装软件,用爬虫爬一些数据,再用Word2Vec, 百度Senta一套,这就好像手上只有个榔头,所以看任何问题,就只好把它描述成钉子。
这是我看到社会计算或者计算社会科学的研究中大概最严重的两个问题。
一个研究是怎么做出来的,它不会是一笔资料出来的,你要整合各种资料。处理资料的技术,而且还不止一个技术,好几个技术要进来,也不是一个方法就完成了。所以你一定十八般武艺都要会。方法学会后,你一定要知道它到底是在那个房子中间的哪一个阶段使用、怎么去定位。这就是方法论的价值。
你怎么样要把这些方法综合起来,最后解决一个我们真正关心的问题,这就叫方法论。
社会计算包括两个面向,一个面向是计算技术怎么被社会性给增强。社会计算的第二个面向,是计算技术怎么去帮助做Social Study和Social Dynamic,社会动态研究和社会研究是因为大数据资料的成熟以及计算技术发展到今天才可以去做一些东西。

社会计算方法论的核心问题
社会计算的方法论核心是什么?既然你要研究社会问题,而Social Study又和大数据与计算技术高度相关,你势必会把你的资料、你的算法和社会现象的预测、解释及理论整合起来。
当你想了解什么是社会,如何用社会研究增强计算技术时,只有预测模型是不够的,对你而言,一定会更好奇的是,买奶粉的还会买啤酒,预测好准,但有没有办法推论?这个现象在中国存不存在?这个现象美国城市存在美国郊区存不存在?那个时代存在,今天还存不存在?不管是数据挖掘出来的是最佳的预测因素(predictors)、行为模式(behavioral patterns)还是预测模型,都是一次探索性的研究,挖掘得到的发现不就是止于此,还该有如下的研究步骤:
探索性研究帮我们找到了推论的理论基础,还该有进一步的理论验证性研究,如下面所示,才能验证理论,找到推论的边界,进行有意义的推论:
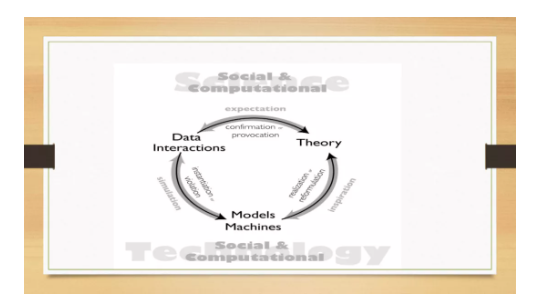
上图是Journal of Social Computing第一期主篇寄语中提出的方法论概念,好的研究一定是在探索、验证、又探索、又验证中循环往复得来的。所以它会是在资料挖掘、模型建立(包括预测的与解释的)以及理论对话的三角对话中得到。你看一篇论文的时候,你可能看到的只是一篇,但是一个好的学者,可能实际上他写了好几篇相关论文。
这个研究已经做好几轮,然后他把这好几轮的研究成果分成三四篇论文,所以你只能看到其中一小段,但实际上他在做研究的时候,可能是不断往复地资料挖掘、对话理论、设计模型、解释模型,再拟合资料……一轮又一轮,使理论越来越精微,预测模型也越来越准,这样才能够把研究做好。这就是我特别强调今天要讲到的核心,什么叫方法论?你怎么去组合那些方法,来一轮又一轮地推行探索与验证,最后来解决一个问题。
社科、管理理论在社会计算研究方法论中为什么重要?圣塔菲研究所前所长Geoffrey West曾说强子对撞机中每秒钟发生6亿次碰撞,用当时全世界的计算机所有算力全部来计算,只能算到对撞所产生的1/60的资料。West说,还好,我们已经有理论知道要怎样寻找一个什么粒子。理论已经告诉你,这些资料中间只有1/100万的东西是有用的,所以只用欧洲核子研究中心的计算机就能算得了。这就是为什么理论对数据分析这么重要。
方法论大论战大概差不多每三四十年会来一次。我读博的时候,正好恭逢其盛。因此,那时候特别重视所谓的科学哲学和科学方法论的课程训练。那时候讨论的就一件事,数据驱动得到的到底是什么?每一次得到的结论都很简单,数据驱动得到的是探索性研究,探索性研究不是一个研究的终结,探索性研究之后,还是要做验证性研究,才能够完成一个推论的过程。
那时候我们读Popper的理论,就是「黑天鹅」论,数据的归纳得到推论「天鹅都是白的」,但一只黑天鹅飞出来,推论就失败了。所以后来建立了逻辑实证论的方法,以理论演绎、随机抽样可以得到一定机率下理论的成立。
我们那时的争论,是因为电脑和统计软件如SPSS、SAS盛行,大型资料库如General Social Survey出现,动辄可以用几万笔数据跑两千个变量的模型,用forward selection、backward elimination、all possible方法「挑拣」出最佳预测模型,社会学界也是流行path model,基本上就是不要理论的统计探索研究。
为此,我读了一个应用数学硕士,还在博后期间去了柏克莱加大统计系访学,跟在Donald Rubin、Cliff Clogg、Smith Herbert、Paul Holland以及David Freeman等统计大师的阵营中学习方法批判。他们主张的正是今天在社科、管理研究中看到的「标准论文」写法:主题、过去的文献、本文的理论贡献、形成的假设和其他理论的对话、研究设计、资料收集、统计验证。
再一次新数据、新方法来袭,数据驱动的研究开启了一大片桃花源,但太阳底下无新鲜之事,一方面社科、管理理论与对真实社经现象的定性观察、定量调查不会被偏废,但另一方面每一次新数据、新方法又会引起社会科学研究的典范转移,从研究的方法论及方法,到新理论的发展及建构理论的方式,都会有大转变。
今天我又正当风口,正在探索这些方法与理论的转变。
回到老例子,在美国城市,尿片和啤酒放在一块销量都很好,能不能推广到中国,不知道,隔20年之后在美国是否还适用,不知道。怎么办?你要想做推论,你就要为它找到理论──美国中产阶级的生活风格是造成这种销售规律的重要因素。这些因素在中国存不存在?20年之后存不存在?如果存在就表示它还可以推论到中国,到未来。
社会计算研究要避免三无
因此,我以为社会计算要避免三无:一叫做无病呻吟,二叫无根之兰,三叫无的放矢。
一叫无病呻吟。你手上一堆工具,然后拿什么资料就空论侃一通,没有找到真实的社会、经济、管理的现象去解题,扎入人与社会的真实需要中作出研究。
二叫无根之兰。意思就是说我只有一个预测模型却无解释模型,无根之兰对于纯粹应用为目的的研究影响不大,但对于想作出重大决策,想作理论建设,想推论到更大范围的人而言,就是致命的不足。其实后面我也要说,文理兼融的大数据研究对应用为目的的研究也极有意义。
三叫无的放矢。这是你有什么资料去炒出什么菜, 反正资料从网上爬下来,我就在那上头开始做分析,也不问问你在作研究的议题是什么,这资料够吗?这资料对吗?
以上三个都要避免,知道什么社会、经济、管理问题是对我们有意义的,不只要预测,也要解释。做学者一定要有一个精神,不要抱怨资料太少,从来资料都少。如果有朝一日资料很多,就表示你是一个很烂的学者,理由很简单,这么多资料人家早做完了。傅斯年讲过:上穷碧落下黄泉,动手动脚找材料。现在还要说上穷碧落下黄泉,动手动脚找算法,既要找材料也要找算法,一起来解决一个真实的问题,提出真实的理论,这才是我们希望推动社会计算要做的事情。
04社会计算应用:如何战略性地使用大数据? 大数据已经流行二十来年,这是许多企业关心的问题,也是社会计算研究的对象。但从学者的角度看,许多企业对大数据的使用仍然缺乏战略考量。这里仅跟大家分享战略性地使用大数据的几个要点:
第一,好好地整理资料,把资料可能整理成结构化资料。比如说前面讲到有企业把所有已经有的大数据可以整理出一堆「多功能」使用在各方各面的资料,比如这些数据可以先把它转成人际关系网络,进而开展研究。又比如,有地理信息。用户家住在哪里,他家房价是多少,他生活风格是什么,他平常都走过哪些地方,他星期六星期天消费是在哪些地方,那些地方的房价是多少等等。
第二、把全部问题列一个清单。大家很少把工作中遇到的这些问题当作老板的战略性问题。中层营销经理要解决的是,广告能不能投得更准?中层产品经理要解决的是,能不能找客户需求更准……这里有一个非常重要的概念,哪些数据当你这整理完之后才是common数据,也就是大家都能用的结构化的数据?已经有一群叫做杂乱无章的电子印记的无结构化数据,我要整理一些成结构化,比如说变成朋友和朋友之间的网络数据,地理数据,客户偏好数据,哪些数据是common数据?
第三个,要企业高层经理与外脑专家参加顾问会。这种研究一定要跟最主要领导人要有高度共识,他才会认为这些大数据使用是战略性使用,而不限于一些功能性的使用。战略最主要的是社会环境、技术环境、制度环境、商业模式环境,这些环境在发生什么变化?好的、整体性的大数据研究要最终能服务战略性的需求。
第四个,找到问题的可能解决路线图。很多问题是大数据不可解的,至少你目前拥有的大数据不可解,或者在今天技术上不可解。但是要搞清楚哪些问题是可解的,把问题变成议题。最后要把议题变成可执行方案,再讨论哪个东西需要哪些算法、还缺哪些数据等等,真正可以拆分下去工作,又从议题转成执行的路线图。
这样把大数据资源作了统筹整理与规划,才能够节省重复整理数据,又重复计算的浪费,更可以从这些数据中看出还能解决一些什么样的重大问题。
 微信公众号
微信公众号